

- The choice between prompt engineering and fine-tuning depends on economics, latency, compliance needs, data patterns, and application-specific failure modes.
- Prompt engineering offers agile, inference-time control and speed, while fine-tuning is a capital-intensive training-time lever for consistency.
- Successful teams start with prompt engineering to validate use cases, then fine-tune only when data clearly proves necessity.
Table of Contents
- Prompt engineering vs Fine-tuning – A clear comparison
- Why choose prompt engineering for AI optimization
- Why choose fine tuning for AI model accuracy?
- Prompt engineering vs Fine tuning: Cost and performance trade-offs
- Comparative analysis: Prompt engineering vs fine-tuning
- Hybrid approach: Combining prompt engineering and fine-tuning for optimal AI
- How does HitechDigital enable both approaches
- Choosing the right AI approach: Prompt engineering vs Fine-tuning
- Conclusion
In AI deployment, the debate between prompt engineering and fine tuning is rarely about which technique is universally “better.” It’s about economics, latency and the specific failure modes of your application. A team can waste weeks fine tuning models that simply needed better context, while another keeps burning money on massive token counts for prompts when a small, fine-tuned adapter would have been faster and cheaper.
The reality is that these are not mutually exclusive tools but different levers for AI model optimization. Prompt engineering is your agile, inference time lever, while fine tuning is your capital intensive, training time lever. Making the right call requires looking beyond the hype and analyzing your specific data patterns, compliance needs and volume scales.
Prompt engineering vs Fine-tuning – A clear comparison
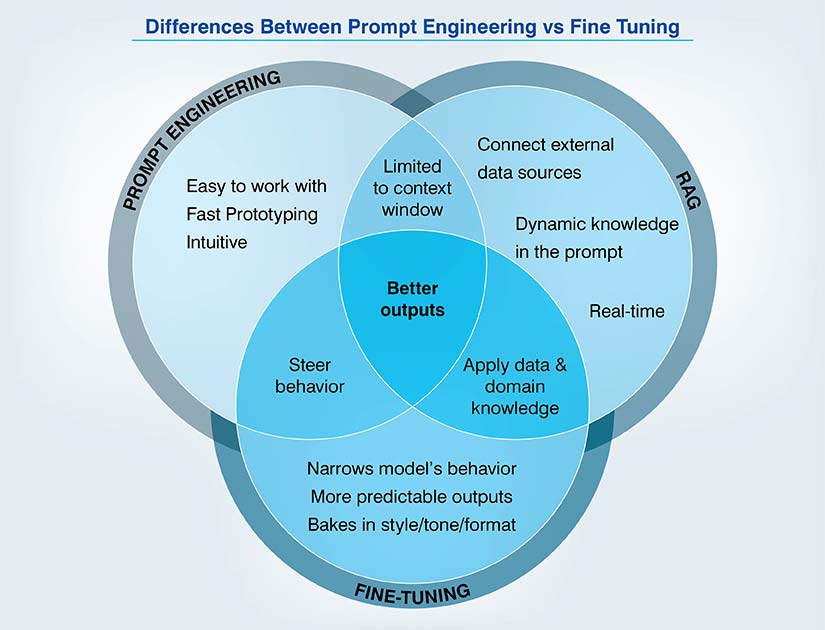
To determine which method is best for a company, you need to understand where the “learning” lives.
Prompt engineering for LLMs is the art of guiding a frozen model. You’re not touching the model’s brain (its parameters); only the inputs are tweaked to guide its existing knowledge and response pattern. Fine tuning, on the other hand, comprises updating the model’s internal weights using a specialized dataset. We do not describe what we need every time we need a response (as in prompting), but train the model to internalize the task, style or domain knowledge.
Here is a tabular representation highlighting the differences:
| Dimension | Prompt Engineering | Fine-Tuning |
|---|---|---|
| What It Is | Strategic guidance for a frozen LLM | Structural training of the model |
| Model Impact | No parameter changes | Internal weights updated |
| How It Works | Carefully designed inputs | Domain-specific datasets |
| Key Techniques | Contextual prompt chaining Schema-driven outputs (JSON/XML) |
Full fine-tuning PEFT methods like LoRA |
| Control & Predictability | High control via frameworks | Learned behavior over time |
| Operational Effort | Fast to deploy, low compute | Higher cost, longer cycles |
| Business Analogy | Precision instructions | Formal specialization training |
| Best-Fit Use Cases | Rapid iteration, accuracy-driven tasks | Deep domain intelligence |
| Business Outcome | Exact, reliable responses at scale | Embedded expertise and consistency |
Why choose prompt engineering for AI optimization
Prompt engineering for LLMs is generally a faster and less expensive solution than fine tuning a model. There are three key reasons why a team should consider using prompt engineering:

When you need rapid, low-cost optimization
A major benefit of using prompt engineering is that it can be implemented in a matter of seconds. Unlike fine tuning a model, prompt engineering does not require retraining a model. Therefore, a team can experiment with different prompts and evaluate the effectiveness of those prompts in mere minutes. Additionally, unlike fine tuning a model, prompt engineering does not consume large amounts of computing power.
As mentioned earlier, prompt engineering is typically much less expensive than fine tuning a model. When a model is modified during fine tuning, the cost of modifying the model includes the cost of the computing resources used to fine tune the model. Since prompt engineering does not require fine tuning a model, the cost associated with modifying the model is negligible. From a cost and scalability perspective, understanding what is prompt engineering helps explain why many teams prefer prompt-based optimization over resource-intensive fine-tuning.
When you require high control over instruction flow
There are certain types of tasks that require the model to follow a strict logical path. For example, when completing a multi-step workflow, it is often beneficial to divide a large task into smaller steps. Prompt engineering is ideal for the following types of tasks:
- Reasoning tasks – Prompt engineering enables a team to instruct the model to show its work in addition to providing the final response.
- Multi-step workflows – As previously stated, prompt engineering enables a team to divide a large task into multiple smaller tasks that the model must complete in a specific order.
- Retrieval-augmented setups (RAG) – Prompt engineering enables a team to retrieve external data to support the model’s responses.
- Context-sensitive agents – Prompt engineering enables a team to create chatbots that can adjust the model’s responses based on the user’s previous inputs.
Additionally, using prompt chaining enables a team to control the logical flow of the model at every step of the process.
When you need explainability and debuggability
Prompt engineering can examine instructions provided to the model thus leading to high degree of explainability and debuggability. Since prompts are text-based, a team can review the prompt and identify potential errors or misunderstandings.
Furthermore, since prompts can be easily edited and updated, a team can quickly make modifications to the prompt and test the revised prompt to determine the impact of the modification on the model’s output.
Therefore, prompt engineering is ideal for the following types of projects:
- Projects require high levels of transparency and accountability.
- Projects that require rapid iteration and development.
- Projects that require significant modification to the model’s behavior.
When hallucination reduction is a priority
One of the primary issues with AI models is hallucination. Hallucinations occur when the model produces a response that is not supported by the available data. Hallucinations are usually attributed to poorly constructed prompts.
Fine tuning can fix deep gaps in domain knowledge and prompting allows us to address reasoning failures quickly. Prompting uses retrieval-augmented-generation (RAG) to inject verified external data into the prompt and ground the model in fact.
This helps avoid retraining the model. Prompting with RAG and live data feeds works better because fine-tuned knowledge has a cut-off date (when training stops).
Using structured prompt engineering techniques can reduce the likelihood of hallucinations. Additionally, it enables a team to constrain the model’s behavior and limits the creative license for the model.
Why choose fine tuning for AI model accuracy?
Prompt engineering has limitations. When those limitations are reached, fine-tuning AI models becomes the most effective approach for improving accuracy and ensuring consistent AI outputs.

When the model must learn your domain
General models lack knowledge of specialized domains. Workflows used in legal, financial and medical industries use unique terms and logic that general models are unfamiliar with.
Fine-tuning solves the issue by teaching the model the terminology that relates to your domain, the pattern that applies to each of your tasks and the consistency of formatting.
While prompt engineering may be able to help enforce some level of reliability; it may not always be able to ensure reliability.
When scaling output volume
Scaling is a tipping point for costs and resources. Prompting imposes a token tax on every API call, when you are sending instructions. Fine tuning allows you to move those instructions into the model’s weights and thus shortens the input prompt.
You need to decide the economics of break-even queries per month where, once you are beyond this volume, the amortized cost of fine tuning is lower than the recurring cost of processing long, complex prompts.
When prompting alone cannot achieve accuracy
There are certain edge cases where the model needs significant changes. For example, if you need the model to accurately classify user intent, or extract entities from unstructured data, then prompt engineering may not be effective.
Fine-tuning enables you to modify how the model interprets the input information. Therefore, fine-tuning allows the model to identify patterns that the model would otherwise ignore.
When data patterns are stable
If your input/output follows a predictable pattern, then fine-tuning is suitable. The model learns the pattern once and repeats the pattern indefinitely. Training models for repetitive tasks is more reliable than relying on managing large numbers of prompt chains.
Prompt engineering vs Fine tuning: Cost and performance trade-offs
Typically, the decision comes down to budget and operational considerations.
Speed of deployment
The time required to deploy varies greatly across both methods. Prompt engineering could take hours or days, which means that you could develop, test and utilize a new prompt within an afternoon!
Fine-tuning typically takes days or weeks, and requires preparation of your dataset and waiting for training time.
Cost-benefit matrix
Use the following cost-benefit matrix to decide whether prompt engineering or fine-tuning fits your LLM goal and delivery timeline. It compares upfront cost, speed to ship, domain depth, ongoing upkeep, and the situations where each option performs best.
| Feature | Prompt Engineering | Fine-Tuning |
|---|---|---|
| Upfront Cost | Low | High |
| Time to Market | Fast (Hours/Days) | Slow (Weeks) |
| Domain Specificity | Moderate | High |
| Maintenance | Easy (Edit text) | Hard (Retrain) |
| Ideal for | Prototyping, Logic, RAG | Style, Format, Deep Domain |
Infrastructure and talent requirements
Fine-tuning requires the following: labeled datasets, high-performance computing equipment (GPUs), and personnel skilled in training models. Fine-tuning is a resource-intensive activity.
Prompt engineering has a different set of skills. You need to understand how the model thinks, and recognize patterns. While prompt engineering does not require a large amount of hardware, it does require you to understand how LLMs function.
Maintenance overtime
Maintaining prompts is relatively simple with version control and minor adjustments.
Fine-tuning is rigid in its approach to maintenance. Every change in data or facts could force you to retrain the entire model. That’s expensive over time.
Evaluation complexity
Evaluating a prompt is relatively straightforward. At HitechDigital, we perform automated A/B testing for all our prompt evaluations. You simply compare the output and select the winning response.
Evaluating fine-tuning is more complicated. You need to verify that the new model has not lost sight of its original training while acquiring the new task.
Comparative analysis: Prompt engineering vs fine-tuning
Let’s look at how they compare the metrics that matter.
| Metric | Prompt Engineering | Fine-Tuning |
|---|---|---|
| Accuracy | Boosts reasoning & general logic. Good for broad tasks. | Improves domain knowledge & patterns. Wins on deep, specific tasks. |
| Hallucination control | Immediate control via frameworks (CLEAR, RISEN). Restricts freedom. | Reduces errors by training on ground truth. Model “learns” facts, reducing invention. |
| Scalability | Easy scaling, high per-token cost. Requires sending long instructions. | High upfront build cost, lower run cost. Cheaper at scale (shorter prompts). |
| Flexibility | High flexibility. Adapt to new tasks instantly. | Rigid. Powerful for narrow, repetitive tasks. |
Hybrid approach: Combining prompt engineering and fine-tuning for optimal AI
A hybrid setup works because prompt engineering and fine-tuning solve different problems.
Fine-tuning changes what the model “knows” and how it behaves by default. It helps it pick up domain language, preferred structure, and consistent decision rules. Prompt engineering controls what happens at runtime.
It pushes the model to follow steps, use tools (like RAG), stick to constraints, and format answers for a specific audience. Put them together and you get a model that understands the domain reliably, then responds with predictable logic and communication.
Why the hybrid approach works
- Fine-tuning sets the baseline. The model becomes better at the domain’s vocabulary, intent patterns, edge cases, and style expectations.
- Prompts handle situational control. You can enforce tone, reading level, risk disclosures, citation rules, and “answer only from retrieved sources” behavior per request.
- RAG stays clean. Fine-tuning improves question interpretation and reduces misreads. Prompting ensures the model uses retrieval results instead of guessing.
- You separate “learning” from “operating.” Stable domain behaviour goes into the model. Fast-changing rules and response policies stay in prompts.
How does HitechDigital enable both approaches
We provide the infrastructure to handle the whole process of combining the methods of prompt engineering and fine-tuning.
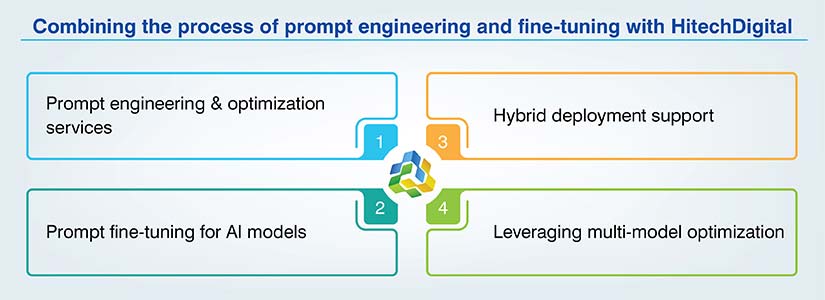
Prompt engineering & optimization services
We don’t just write prompts. We engineer them. We use structured prompts and prompt chaining. Our teams use frameworks like RISEN and CLEAR to keep outputs consistent. We back this up with testing to prove the prompt works.
Prompt fine-tuning for AI models
We only move to fine-tuning after we can confirm that the model’s performance has stopped improving due to prompt engineering. This ensures we never waste resources training a model to address a problem that could be solved with a single prompt.
When aren’t enough prompts, we do heavy work. We prepare and clean the data. We handle model training. We evaluate everything to make sure the fine-tuned model is better than the base model.
Hybrid deployment support
We help companies decide. We integrate these models into your current workflows. We set up prompt libraries and version control, allowing your team to manage updates with ease. Check out the differences between the various prompts here.
Leveraging multi-model optimization
Use of multiple models is a feature of the hybrid approach wherein we design prompts to work across GPT, Claude, Gemini, and Llama.
Sometimes, we fine-tune a smaller, open-source model such as Llama for a specific task and then use a larger model, like GPT-4 with prompt engineering for complex reasoning.
Choosing the right AI approach: Prompt engineering vs Fine-tuning
This table gives a quick, practical way to decide whether prompt engineering will get you to production, or whether you’ve hit the point where fine-tuning makes more sense. It maps the choice to what teams face day to day task complexity, data readiness, latency, and whether KPIs hold up in real usage.
| Decision Factor | Prompt Engineering | Fine-Tuning |
|---|---|---|
| Task Complexity | Best for complex reasoning | Best for repetitive patterns |
| Data Readiness | No labeled data required | Requires curated datasets |
| Cost & Effort | Low cost, fast iteration | Higher training investment |
| Latency Needs | Multiple prompts may be needed | Faster responses, fewer prompts |
| Behavior Control | Fix logic and format issues | Fix knowledge and style gaps |
| Starting Point | First approach to try | Escalation path |
| Evaluation Step | Measure accuracy, consistency | Validate learned behavior |
| KPI Outcome | Deploy if KPIs met | Train if KPIs missed |
| Failure Analysis | Refine prompts or frameworks | Retrain with better data |
| Recommended Flow | Use RISEN, then assess | Apply when prompting plateaus |
Conclusion
The choice between prompt engineering and fine-tuning is not about which is better than the other. Good AI development refers to the use of right tool at the right time. Prompt engineering provides control and speed while fine-tuning is beneficial for extracting deep knowledge and maintaining consistency.
Most successful projects have no issues starting with prompt engineering. This approach helps in validating the use case first. One can move towards fine-tuning only when the data shows that you need it.
Irrespective of whether you are optimizing workflow today or building a unique model for the near future, you need a clear idea of what you want to solve. And then make the choice!




