






Custom data collection, moderation, and annotation to accelerate your AI projects

Training models requires massive amounts of high quality, domain specific data. Without structured, validated and representative training data, models fail to generalize, underperform in production and are vulnerable to bias and error. HitechDigital is a trusted data partner specializing in collecting, cleaning, and preparing purpose-built datasets for model training and fine-tuning.
We at HitechDigital offer end to end AI training data services for enterprise scale AI development. Our services include data collection, cleansing, moderation, annotation and labeling across image, audio, video, text, sensor and synthetic datasets. We also generate synthetic data for rare or sensitive use cases, structure datasets for LLM fine tuning and verify and validate for quality assurance to power applications in generative AI, LLMs, chatbots, virtual assistants, computer vision and facial recognition systems. We help our clients reduce model drift, get faster deployment cycles and more reliable AI outcomes.
Our procedure incorporates unique workflows, automation and human in the loop techniques. Secure pipelines control ingestion, cleansing, annotation and augmentation with applicable industry standards. Data validation frameworks flag inconsistencies early on, and quality checks along the way verify your training data matches the developing objectives of the model. Our secure and scalable infrastructure allows for larger and or more complicated projects without hindrance, and with integrated software for labeling, moderation and verification we streamline each stage of dataset preparation so that our partners can deploy AI innovation with production ready training data.
100M +
Data points processed across domains
400 +
AI training data specialists
98.7 %
First time response
98.5 %
On-time project delivery
Enhance AI model performance with precise, scalable, and impact-driven training data.
Boost Your AI Model Now →End-to-end AI training data services designed to optimize model performance and outcomes.





More than 95% of our clients are recurring, a testament to the unwavering trust and satisfaction our services consistently deliver.
Operations Director, Technology Company, New York
CTO, Food Waste Assessment Solutions Provider, Switzerland
Head of Data Science, Data Analytics Company, California
Diverse AI applications powered by precise, well-structured training data.
AI training data to enable models to learn patterns, structures, and relationships, ensuring accurate, diverse, and high-quality outputs for applications like content creation, synthetic data generation, and predictive analytics.
AI training data to teach the model grammar, facts, reasoning, nuances of style, generate coherent text, and improve natural language processing to enable human-quality text generation and understanding.
AI training data enabling natural language understanding, context-aware responses, and personalized interactions, ensuring seamless communication, improved accuracy, and enhanced user experiences.
AI training data in the form of conversational text and dialogues to enable chatbots to understand user queries and intent to deliver accurate, context-aware responses, personalized interactions, and engaging interactions.
AI training data in form of facial images accounting for variations in lighting, angles, and expressions to improve accuracy, detect features, recognize identities, ensure bias mitigation, and enable secure authentication.
Diverse training datasets for fueling algorithms to “see” and interpret visual information effectively for accurate object recognition, image classification, and scene understanding.
Train smarter with diverse data types for robust AI models
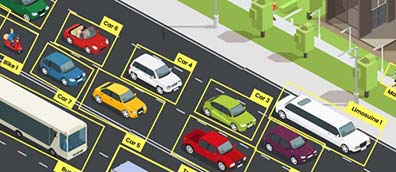
Labeled images provide ground truth for AI model training in image recognition tasks.
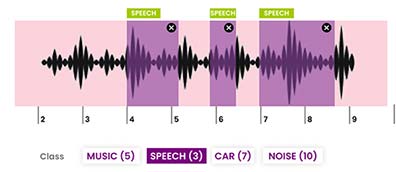
Sound recordings, transcribed, and annotated, used for training speech recognition models

Labeled sequence of images used for motion analysis, object detection, and scene understanding
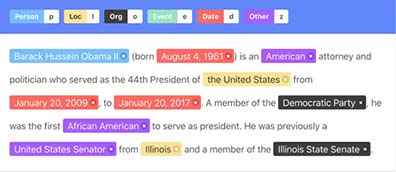
Texts, labeled or unlabeled, for NLP models to understand language, context, and generate insights.

Sensor data for IoT, robotics applications to provide real-time insights for predictive analytics.

Artificially generated data mimicking real-world data, used for AI model training/testing
Scalable AI training data solutions tailored to sector-specific AI needs.
Powering autonomous driving, in-cabin monitoring, and predictive maintenance for enhanced vehicle safety.
Boost personalized recommendations, optimize inventory, and enhance customer experience.
Building advanced AI models, improving virtual assistants, search engines, and personalized user experiences.

Enabling medical image analysis, disease diagnosis, personalized treatment plans, and drug discovery.
Partner with us for expert-led, impact-driven AI training data services.

Delivering high-quality, customized training data solutions.

Custom datasets designed for your AI model’s unique needs.

Reliable, precise data for optimal AI model performance.

Efficient solutions for projects of any size or scope.

Sourced responsibly to ensure fairness and inclusivity.

Multiple projects successfully delivered in diverse sectors.
We collect multimodal datasets including image, video, text, audio, sensor and synthetic data for AI training. These datasets enable large language models, computer vision systems, generative AI and virtual assistants to perform across various applications and ensure reliable outcomes for domain specific and enterprise AI projects.
Yes, we generate synthetic data for client models, for edge cases and rare scenarios. We use augmentation pipelines to expand training datasets for generative AI. Through augmentation pipelines we extend generative AI training sets, LLM tuning and facial recognition systems. This helps with model generalization while solving privacy limitations in sensitive AI training and business applications.
We use automated classifiers and human moderators to moderate AI training data. Moderating scored data will flag and remove offensive, bias, or policy violating content. Ensuring an ethical AI dataset allows for generative AI, chatbots and LLM building while also ensuring compliance and AI safety in regulated and consumer facing industries.
We use synthetic oversampling, noise injection, translation, rotation, audio modulation and text paraphrasing to augment datasets. These machine learning data augmentation methods increase dataset diversity, reduce bias and improve generalization for generative AI, chatbots, computer vision and LLM models making them more robust in production and large scale business use cases.
We structure raw datasets into tokenized, aligned and context rich formats for LLM fine tuning. Domain specific corpora are curated, cleaned and formatted into structured pipelines so models can train effectively. This enables large language models to have better contextual understanding and accuracy across enterprise, research and generative AI applications.
Validation and verification includes statistical benchmarking, cross-sampling, comparison to ground truth and human quality checks. These data validation processes for AI ensure accuracy and consistency in data used to train generative AI, LLMs, chatbots and computer vision models, reduce training errors and compliance to regulations and requirements for deployment in real world.
We support various input and output formats like JSON, XML, CSV, TXT, MP4, WAV, PNG and proprietary schema. This flexibility allows for easy integration of AI training datasets into machine learning pipelines, large language model fine-tuning and generative AI development in enterprise scale environments.
We have strict data privacy standards with GDPR, HIPAA and ISO compliance. AI training data is encrypted, anonymized and access controlled. These security controls ensure enterprise grade governance is applied to datasets used for LLM training, generative AI and face recognition systems and sensitive data is protected across the AI data lifecycle.
Our rates are based on dataset type, project size, annotation difficulty and turnaround. We offer transparent, scalable AI training data service pricing for businesses building generative AI, large language models and computer vision applications with predictable costs and quantifiable value across various stages of AI model development.
Turnaround time varies with dataset size, data types and complexity of annotation. Small projects take weeks but enterprise level AI data preparation requires phased delivery. Our scalable processes ensure timely delivery for generative AI, large language models and computer vision datasets to get models trained and deployed faster.
We use distributed data pipelines, cloud infrastructure and automated workflows to scale AI training data operations. Large generative AI datasets, LLM fine-tuning and computer vision datasets are processed efficiently. Human-in-the-loop checks ensure high quality at scale, so projects don’t get delayed for enterprise AI training and deployment needs.
Yes, we create custom AI training data solutions for domain specific use cases like healthcare imaging, autonomous vehicles and industrial IoT. By adapting annotation, validation and structuring workflows we provide high precision datasets for specialized AI models so clients can get accuracy, compliance and scalability in specialized AI deployments.
Prioritizing client’s growth, fostering trust, collaboration, and leading with empowerment to achieve shared success.

Bachal Bhambhani
Sr. Vice President, SalesBachal represents HitechDigital in North America, and helps client and our production teams collaborate effectively on projects and partnership initiatives.

Snehal Joshi
Director, Data Solutions & BPMSnehal, a seasoned leader, manages a large data team. He's delivered numerous projects, driving growth through process innovation for clients across industries.