

- Data quality determines the success of AI projects more than model architecture today as architecture has more or less gained standardized forms. It is the training data that now determines how the model will behave in real-world scenarios.
- Mixing data labeling and data annotation causes model failures, impacted accuracy, regulatory compliance and commercial viability.
- High-quality annotation for training datasets give your AI model the understanding required to make it a robust, mission-critical production systems.
Table of Contents
- What is data annotation
- Why data annotation powers AI perception and reasoning
- Use cases where data annotation is essential
- What is data labeling
- Use cases where data labeling is enough
- The core differences: Data labeling vs Data annotation
- How the difference impacts model performance
- Cost, quality, and ROI: Data labeling vs Data annotation
- Data labeling vs Data annotation: Choosing the right approach
- Conclusion: Data is AI’s operating system
Artificial intelligence has evolved from experimental AI prototypes and is successfully fueling autonomous vehicles, medical diagnostics, fraud detection, personalized commerce, and multimodal conversational platforms. However, till date the point of discussion always is about foundation model and it’s architecture, GPU capacity, etc. No one talks about the attribute that determines the success of AI models and projects. It is training data quality.
Data is not the fuel for AI systems. It is a control system. What the AI model learns, ignores and how it behaves in real world scenario; all of these falls back to how training data was prepared. This is exactly where treating data labeling and data annotation as interchangeable causes expensive failures.
These two are not the same, and understanding the difference between data annotation and data labelling is no longer an option, as it directly impacts the accuracy and commercial viability of your AI model. This is an effort to clarify what each really means, when to use which approach and how the correct usage affects enterprise AI outcomes.
Struggling to decide between data labeling and annotation?
Hire skilled data annotation experts to build the right data strategy aligned to your model goals.
What is data annotation
Data annotation is the process of adding meaning and context to turn raw images, text, audio, and video into structured datasets for the machine learning models to learn patterns and make decisions. More than identifying objects, data annotation encodes where the object is, how the object behaves, and how it relates to its environment.
For computer vision models, data annotation means
- Localize objects using bounding boxes.
- Define precise object boundaries using polygons and segmentation masks
- Describe posture, pose, and geometry with help of keypoints and landmarks
For natural language processing, data annotation means
- Entity linking and coreference resolution
- Intent classification and relationship extraction
- Named entity recognition (NER)
For video and sensor data, annotation means
- Event detection and activity recognition
- Frame-level labeling
- Object tracking across time
These structures actively teach spatial, temporal, and semantic relationships to your models. Without data annotation, AI systems may identify patterns but understanding scenes, inferring intent, or predicting outcomes is not possible. Data annotation transforms raw data into ground truth.
Why data annotation powers AI perception and reasoning
Modern AI systems, apart from classification, are expected to perceive, reason, and act in real-world environment.
Apart from pedestrians, a self-driving car should understand:
- Where is the pedestrian
- Which direction is the pedestrian moving
- Is the pedestrian on a collision path
- How does the pedestrian relate to vehicles and road boundaries
Spatial and temporal annotation makes this understanding possible for your model.
A tumor is not useful if merely labeled “cancer”, for medical imaging the model should understand:
- Boundaries of the tumor
- Growth pattern of the tumor
- Internal structure of the tumor
- Proximity of tumor to other organs
Annotation allows models to move from recognition to interpretation.
Use cases where data annotation is essential
Real-world AI applications depend on wholly on the knowledge the get from structured annotation. And so data annotation as a process becomes much more than the simple act of labeling. Annotated data holds the key to reliable machine perception using spatial, temporal, and relational data representations.
| Use Case | Why Data Annotation |
|---|---|
| Autonomous Driving |
|
| Medical Imaging |
|
| Retail Shelf Analytics |
|
| Facial Recognition & Biometrics |
|
| Video Surveillance & Behavior Modeling |
|
Above use cases show that enterprise-grade AI models attain operational accuracy only if they are trained using accurate training datasets. Precisely annotated data, which captured context, movement, and relationships, make AI models high-performing and predictable in real-world scenarios.
Want to Improve model accuracy & reduce edge-cases?
Find out how to use precise datasets to accelerate deployment timelines across complex AI applications.
What is data labeling
Data labeling, as a crucial component of supervised learning, is the process where raw data like text, images, video or audio is identified and tagged to provide context to help machine learning models learn from it, and empower AI models to detect patterns, recognize objects, and make accurate prediction.
Data labeling answers a simple question “What category does this belong to?””.
Here are some examples:
- A customer message labeled as “complaint”
- A document labeled as “invoice”
- An audio clip labeled as “speech”
- An image labeled as “dog”
Labeling is a corner stone of the supervised classification model, and enables AI systems to sort, filter, route, and prioritize information. Different types of labels include:
- Discrete and predefined
- Low dimensional
- Single-value or multi-class
In the ML pipeline, labeling occurs during the dataset creation phase. This process starts before model training and is fast and scalable. But mind you, labels don’t contain any structural or contextual information. They say what something is, but never talk about where, how and why.
Use cases where data labeling is enough
Categorical labeling resolves classification problems faster and better than data annotations. Here are some examples where simple tags provide enough learning signal for models to make consistent, and human like decisions.
| Use Case | Why Labeling Is Sufficient |
|---|---|
| Sentiment Analysis |
|
| Spam Filtering |
|
| Product Categorization |
|
| Document Classification |
|
| Survey Response Coding |
|
Above examples prove that applications only require grouping inputs into predefined classes, and well-curated labels efficiently delivers dependable outcomes across high-volume, business-critical machine learning workflows and effectively supports model performance goals.
The core differences: Data labeling vs Data annotation
Data labeling and data annotation differ from each other in several ways. It includes workforce requirements, technical depth, and of course the learning impact. It also helps the organization to choose the perfect data strategy to build a production grade and scalable artificial intelligence systems.
| Dimension | Data Labeling | Data Annotation |
|---|---|---|
| Level of Information Captured |
|
|
| Data Complexity & Dimensionality |
|
|
| Human Effort & Domain Expertise |
|
|
| Impact on Model Learning |
|
|
| Annotation vs Labeling Scope |
|
|
We hope the comparison table showcased above tells why organizations in the processes of building an AI application must rely more on data annotation and not data labeling. Accurate and rich annotations empower your models to understand behavior, relations, and environment for delivering higher accuracy, resilience, and long-term operational reliability.
How the difference impacts model performance
Now that we know what the difference between data annotation and data labeling is, it’s time we discuss how both of them influence machine learning outcomes. It will also show how deeper data representation is actively involved in model intelligence and operational stability in real-world AI environments.
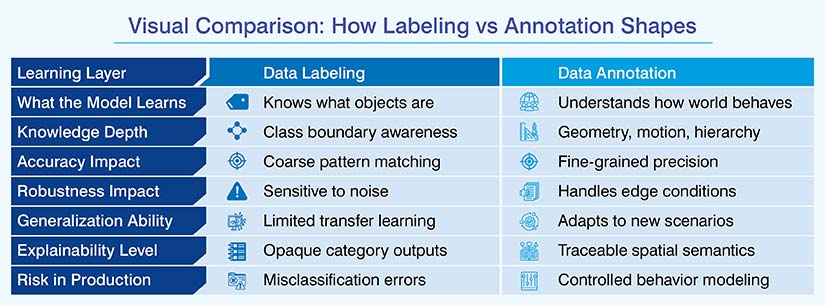
Labeling teaches models what things or objects are. Annotation teaches models how the real-world scenarios are. With labels, a model learns class boundaries. With annotations, it learns object geometry, motion, interactions, and hierarchy. All this directly impacts:
- Accuracy – Fine-grained annotations reduce ambiguity
- Robustness – Models handle edge cases better
- Generalization – Models adapt to unseen conditions
- Explainability – Decisions can be traced to spatial and semantic cues
This side-by-side comparison makes it clearer that while data labels initiate learning, structured data annotations improves performance, prevents bias, hallucinations, and instability. Annotations give precise representations of reality rather than fragile categorical shortcuts.
Cost, quality, and ROI: Data labeling vs Data annotation
We witnessed the difference between data labeling and data annotation, and how it impacts model performance. Now let’s check out the cost, time, effort, and long-term impact of both the approaches. It also shows how taking up short term savings holds the risk of undermining AI performance, whereas taking up a robust and agile data annotation strategy empowers you with sustainable operations and high-performing AI system.
Labeling is cheaper because it is simple. Annotation is expensive because it is complex. High-quality annotation requires:
- Continuous validation
- Domain expertise
- Inter-annotator agreement checks
- Multi-layer QA
- Trained human annotators
However, cheap data results in expensive models. Low-quality data labels lead to retraining cycles, production errors, and customer dissatisfaction. Annotation is an upfront investment that pays back through:
- Regulatory defensibility
- Lower operational risk
- Fewer false positives
- Faster convergence
So now we also know that AI and ML companies, or for that matter any organization that focuses on cost compromises on the long-term reliability of their AI models. But companies that prioritizes structured annotation ensures measurable returns that are far more cost effective than initial data preparation expenditures.
Optimize your AI performance with scalable data annotation workflows.
Get enterprise-grade datasets created with high-precision and accuracy to fast track model development.
Data labeling vs Data annotation: Choosing the right approach
The right approach is not about selecting between the two, instead first define how much real-world environment understanding you want your AI model to have to perform reliably during production. The clarity about this would help you take call whether you need simple labeling or your project needs a full-blown data annotation.
To ascertain this, ask:
- Does failure carry financial or safety risk?
- Does it make real-world decisions?
- Does my model need spatial or temporal context?
- Is it regulated?
If the answer to most of the above questions is YES, you cannot treat data annotation as an option. It becomes a necessity. In such a scenario, expert data annotation service providers equipped with trained annotators, latest tools, and robust annotation workflows required to scale your annotation process. They don’t treat annotation as a backend activity, but a core AI engineering that directly influences model accuracy and operational stability.
Conclusion: Data is AI’s operating system
In modern AI ecosystem, data is not passive input. High-quality data enables perception, reasoning, and trust at scale. Algorithms may become sophisticated and models may scale, but the performance of your AI and ML models depend on the quality of training data. We would like to reiterate the fact that data labeling assigns names, whereas data annotation provides understanding and context.
It’s time enterprises shift their focus from experimentation to mission-critical deployment of data annotation workflow. This will decide if your AI systems will work reliably or fail unpredictably.
Ready to build high-performing AI models with reliable training data?
Partner with our experts for scalable data annotation and labeling solutions tailored to your project need.




