

- Accurate data annotation is the foundation of AI success, creating better models through better training data.
- Well implemented annotation solves ambiguities and edge cases that impact model performance.
- Strategic quality control and human-in-the-loop approaches ensure consistency and reliability in training datasets.
Table of Contents
Companies often struggle with inconsistent labeling, limited domain knowledge, and resource constraints that compromise the quality of the training dataset and impact AI model performance. Accurate data annotation provided by expert services fills this gap between data collection and model deployment in AI.
A study shows when 40% of labels in training and validation sets are incorrect, a model’s measured performance can drop to 46.5%. Professional data labeling solves these problems by delivering consistent, high-quality annotated datasets through expert teams and proven methods.
Effective data annotation includes domain expertise, standardized quality control, and scalability, so the training data meets the requirements for optimal model performance. Companies investing in data annotation for AI get better model accuracy, faster time to market, and better performance—delivering measurable ROI. They reduce retraining cycles and create AI systems that meet business objectives.
Key benefits of high-quality data annotation for AI
Well planned machine learning data annotation strategies gives you high quality datasets that create the foundation for AI success and deliver benefits that impact model performance, reliability, and business outcomes across many applications and domains.

Benefits of Professional Data Annotation:
- Better generalization and robustness: Models trained on well annotated data perform consistently across many unseen scenarios and hold up to real-world variations.
- Faster training and convergence: Labeled data allows algorithms to find patterns faster, reduces training epochs, and shortens development time.
- More confident predictions: Models produce more certain outputs with better consistency, which is important for applications where decisions have big consequences.
- Easier maintenance: Good initial annotation reduces post deployment corrections and retraining cycles and lowers ongoing operational costs.
- Enables complex applications: Annotation captures the subtleties required for specialized AI tools in domains where accuracy is critical.
The role of accurate data annotation in improving AI models
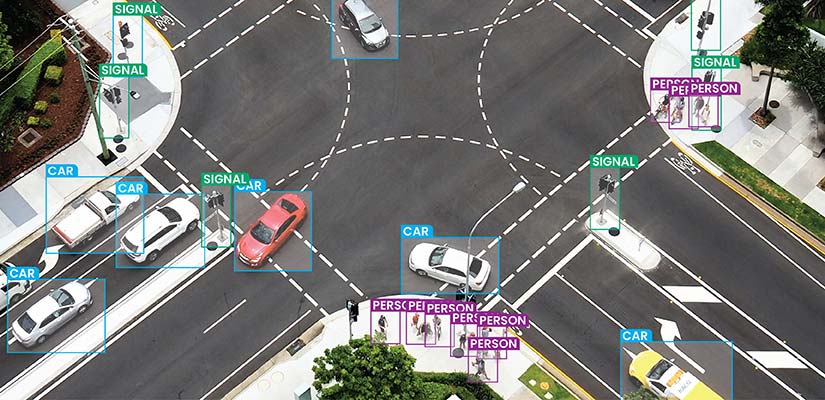
Accurate data annotation serve as the backbone of AI training through multiple critical functions that turn raw data into learning material upon which accurate models are built.
1. Providing the ground truth for AI learning
Professional data annotation establish objective truth, which is the foundation for machine learning. Human annotators meticulously label, categorize, and mark features that the model should recognize. The accuracy of this ground truth directly impacts how well the model learns the correct associations.
For high-fidelity ground truth, human judgment is key in cases that require contextual understanding. For example, when annotating a medical image where a shadow might look like a tumor, a data annotation specialist with medical knowledge can tell the difference between the two based on surrounding tissue characteristics that automated systems might misinterpret.
Thus, by clarifying, the resulting ground truth simplifies real-world complexity accurately, rather than creating vague assumptions.
2. Enabling supervised learning algorithms
Supervised learning algorithms work fundamentally by learning from examples. They need both input data and the correct answers for that data in order to learn. Data annotation helps with this by creating the input–output pairs systematically, effectively giving the algorithm the “correct answers” so it can recognize patterns.
The relationship between annotation quality and learning effectiveness is direct and measurable through the following:
- Faster convergence rates with decreasing loss functions
- Higher ultimate accuracy with fewer training iterations
- More efficient resource utilization during model development
Professional annotation enables curriculum learning approaches in which models are progressively exposed to more complex examples. By calibrating example difficulty, annotation services help design the optimal learning path that builds capabilities systematically rather than randomly. This creates more robust and generalizable models.
3. Simplifying complex pattern recognition
Advanced AI applications require the recognition of patterns across multiple dimensions and need subtle contextual clues. Experts, when conducting data annotation for AI, add detailed labeling to training data so that models can detect complex features and relationships.
In computer vision, this means pixel-perfect segmentation of almost identical objects. For natural language processing, it means annotating linguistic nuances like sarcasm or cultural references. Audio annotation captures the emotional undertones that define how speech is understood.
The granularity of annotation directly correlates with a model’s ability to develop sophisticated feature detectors. When annotation services provide rich, multi-dimensional labeling, models develop internal representations that capture the full complexity of the target domain and make accurate predictions in tough scenarios.
Precise image annotation for food waste assessment

A Swiss food waste analytics company had inconsistent and inaccurate annotations of kitchen waste images. They needed high-quality labeling – bounding boxes, segmentation, classification – for thousands of different food items to build reliable machine learning training datasets.
HitechDigital annotated thousands of food waste images with bounding boxes, segmentation masks, and classification labels. Teams referenced a central food ontology and applied strict quality checks to deliver consistent, high-accuracy annotations ready for model training.
The final deliverables led to:
- 100 % accurate annotated datasets
- Improved food–waste analytics performance
- Actionable, metric-driven insights
4. Reducing model bias through diverse annotation
Algorithmic bias shows up in real-world consequences, such as facial recognition systems misidentifying people with different skin tones or speech recognition failing with certain accents.
Data annotation experts address these systemic biases through stratified sampling and demographic calibration methods. For example, when creating training data for facial recognition, they ensure balanced representation across ethnicities, ages, and genders, and include diverse lighting conditions and camera angles.
For voice assistants, annotation teams include speakers with various accents, dialects, speech patterns, and background environments. Annotation guidelines explicitly address potential bias vectors, instructing annotators on consistent approaches across demographic groups.
5. Clarifying ambiguity and edge cases
AI models fail when faced with ambiguous situations or rare edge cases outside the norm—like self-driving cars struggling to identify partially hidden pedestrians in weird lighting. These edge cases often decide whether a model performs well or exceptionally in real-world use.
Data annotation with specialized workflows methodically resolve ambiguity. For instance, when annotating pedestrians for autonomous driving datasets, expert annotators use consistent protocols instead of making arbitrary decisions. They flag partially visible people for review, use consensus approaches where multiple experts review the same scenario, and create guidelines for more of these cases.
Data annotation teams also use confidence scoring, where annotators rate their certainty and provide valuable metadata for training. This extra attention directly improves model robustness—so vehicles can detect pedestrians in odd conditions that would otherwise result in false negatives or unnecessary braking.
5 Data annotation strategies to improve AI Model accuracy

Professional data annotation uses advanced methods and quality control frameworks to systematically improve annotation accuracy and create consistent high-quality datasets needed to train high-performing AI models.
1. Developing comprehensive annotation guidelines
Professional data annotation requires detailed, unambiguous rulebooks that are the foundation for consistent labeling across large datasets and multiple annotator teams. These guidelines define precise criteria for each label category, provide sufficient examples of correct application, and clear decision trees for edge cases.
Creating effective guidelines is an iterative process that starts with domain expert input and develops through practical application and feedback. Initial versions are tested with sample data to identify ambiguities or gaps, with continuous refinement as new edge cases emerge during the annotation process.
Good guidelines should include:
- Visuals that show correct vs incorrect annotation examples
- Decision trees that resolve conflicts between overlapping categories
- Standardized approaches to handling uncertain cases or partial visibility
- Project specific interpretations of subjective concepts
The quality of these guidelines directly affects annotation consistency. Well documented protocols reduce inter-annotator variation and ensure that resulting dataset provides clear signals for model training.
2. Implementing robust quality control frameworks
Effective data annotation follow multi-layered quality control systems to maintain standards throughout the annotation process.
These frameworks typically include:
| QA Layer | Process | Purpose |
|---|---|---|
| Level 1: Initial validation | Automated checks for completeness and basic conformity | Catches simple errors and ensures all fields are filled |
| Level 2: Peer review | The second group of annotators review samples of completed work | Catches systematic errors or misinterpretations of guidelines |
| Level 3: Expert review | Subject experts review challenging cases and random samples | Resolves complex issues and ensures domain-specific accuracy |
| Level 4: Statistical analysis | Automated detection of outlier patterns or inconsistencies | Catches systematic biases or drift in annotation quality |
These tiered approaches catch errors early and provide valuable feedback to improve annotator performance. The best quality control systems adapt dynamically, increasing scrutiny for annotators with higher error rates or for tricky data subsets.
3. Leveraging Inter-Annotator Agreement (IAA) metrics
Professional data annotation services for ML track Inter-Annotator Agreement (IAA) as a quantitative measure of annotation quality and consistency. These metrics (Cohen’s Kappa, Fleiss’ Kappa, F1 scores) calculate how often different annotators agree on the same answers when given the same data.
High IAA means annotations reflect real patterns in the data and not arbitrary decisions or individual biases. For most use cases, services aim for an IAA above 0.8 (0-1 scale), and even higher for critical use cases like medical or safety systems.
IAA analysis provides actionable insights to improve annotation processes in the following ways:
- Low agreement on specific categories means guidelines are ambiguous
- Consistent disagreements between certain annotator pairs signals training gaps
- Decrease in IAA over time means guidelines are drifting or annotators are fatigued
By monitoring these metrics and addressing the root causes, annotators ensure that all datasets that are delivered have the consistency and reliability required to accurately train AI models.
4. Strategic use of human-in-the-loop (HITL) approaches
These hybrid approaches allow human annotators to focus on the critical issues—complex decisions, ambiguous cases, quality control—while automating the relatively straightforward labeling tasks.
In HITL implementations, initial annotations are generated by existing models or rule-based systems and then reviewed and refined by human experts. This works well for tasks like:
- Pre-segmenting images for human refinement
- First-pass entity recognition in text for humans to verify and expand
- Identifying areas of interest in large datasets to inspect more closely
For highly specialized domains, annotation services integrate subject experts into the workflow at critical stages. For example, medical imaging projects have radiologists reviewing critical diagnostic annotations, legal document processing has attorneys overseeing contract classification, and linguistic projects have native speakers for dialect-specific nuances.
The strategic placement of human attention in these workflows improves annotation quality while keeping costs and timelines reasonable, creating the balance between quality and speed.
5. Utilizing iterative feedback loops
Professional data labeling incorporates systematic feedback mechanisms that connect model performance insights to annotation processes. This closed loop ensures that annotation efforts are aligned with actual model needs and not theoretical assumptions.
The feedback process starts with an analysis of model performance metrics, focusing on the following:
- High error rate categories or features that might show annotation inconsistencies
- Low confidence predictions that might mean insufficient or ambiguous training examples
- Performance gaps across different data segments that might show annotation biases
These insights guide targeted re-annotation efforts, focusing on resources where they will have the most impact. For example, if a computer vision model consistently misclassifies a certain object type, the annotation team might review and update labels for that category across the dataset.
Beyond specific corrections, performance insights inform the update of annotation guidelines and training materials. When model confusion patterns correlate with specific annotation decisions, guidelines can be refined to provide clearer directions for those cases in future projects.
The most efficient annotation services use agile methodologies for this feedback process, with regular review cycles, where model performance metrics directly inform annotation priorities and approaches. This collaboration between data scientists and annotation teams creates a responsive workflow that improves data quality based on actual outcomes, and not static requirements.
Automated text classification for a German construction technology company

A German construction technology company needed to validate and classify thousands of news articles for its AI-driven market insights platform. They had inconsistent tagging, low accuracy, and manual workflows were inefficient, hindering model performance and timely analysis.
HitechDigital implemented a scalable text classification and validation pipeline using NLP and machine learning to categorize and verify article metadata. The automated system enabled consistent, high-throughput processing with human-in-the-loop checks to ensure data integrity and model readiness.
The results were:
- 95% classification accuracy
- 80% reduction in manual validation
- Faster AI insights deployment
Benefits of partnering with a data annotation service provider
Outsourcing data annotation to experts gives you access to specialized skills and operational efficiency to get better AI results. Professional services offer:
- Specialized skills and workforce: Teams of domain experts label accurately with scalable resources, processing large volumes of training data fast.
- Best practices and standards: Established quality frameworks with ISO certifications, proprietary tools and workflows that beat generic platforms.
- Cost effective efficiency: Long term value by avoiding re-labeling cycles, faster time to market with clean data and freeing up internal teams to focus on their strengths.
- Robust data security protocols: Frameworks with infrastructure, access controls and data handling procedures that meet GDPR and HIPAA regulations and often exceed in-house capabilities.
Conclusion
The specialized techniques, quality control frameworks, and domain expertise that professional data annotation bring to the table translate into real-world improvements in AI model accuracy. This creates models that generalize better to real-world conditions, learn more from the data you have, and make more reliable predictions when deployed.
As AI applications tackle more complex and high-stakes domains, this partnership between human annotation expertise and machine learning capabilities is key to success. Businesses that invest in quality data annotation will be best positioned to build AI systems that deliver on the promise.




