

- AI training data forms the foundation of machine learning model performance and decision-making.
- High-quality, well-annotated data directly impacts model accuracy, generalization, and fairness.
- Strategic data practices including preprocessing, augmentation, and bias mitigation—enable responsible, scalable, and future-proof AI systems.
Table of Contents
- What is AI training data
- Why high-quality training data is important for machine learning
- Different types of AI training data
- Key challenges in training data management
- Collecting and annotating data for AI training datasets
- Preparing data for model ingestion
- Expanding datasets with synthetic data and augmentation
- How to handle ethical risks and bias in training data
- Conclusion
Organizations often struggle to get the expected results from machine learning implementation. These disappointments stem from not paying enough attention to AI training data, which is the foundation for training ML models.
AI training data is the experiential basis that enables algorithms to identify, understand and represent patterns. When correctly selected and prepared, the models trained on these accurately annotated datasets can better understand real-world events and make dependable predictions across different scenarios.
The strategic advantages of the training data in machine learning are not limited to technical performance but help create a competitive difference. A report shows that the AI training dataset market will grow to USD 14.67 billion by 2032. This highlights the growing importance of training data in AI implementation across industries.
Organizations adopting data-centric practices build more capable AI systems that perform reliably and adapt better to new situations. These systems deliver consistent results over time and deliver business value across applications.
What is AI training data
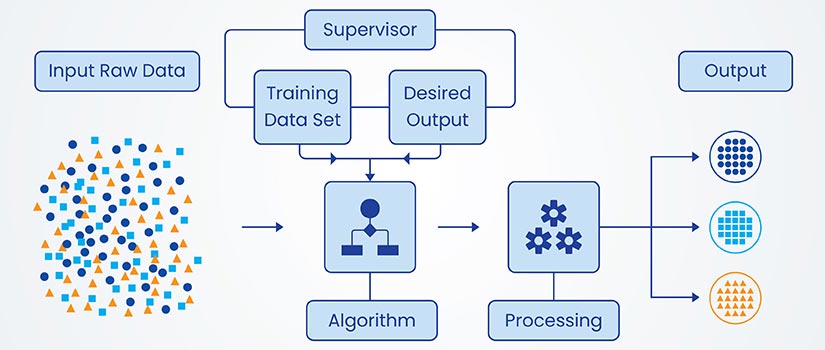
AI training data are sets of examples used to teach machine learning algorithms to identify patterns and make predictions. In machine learning, training data consists of input features (observable characteristics) that are connected to output targets or labels in supervised learning scenarios.
Each training data sample is an example that helps the model adjust its parameters and improve through iterative optimizations.
The composition of data for AI training determines the patterns that the model can recognize and the tasks it can perform. This differs from validation data (for hyperparameter tuning) and test data (for final performance evaluation) as training data determines the model’s internal representations and decision boundaries.
This is fundamental in the machine learning data pipeline, as each dataset serves a different purpose in the model training lifecycle.
Why high-quality training data is important for machine learning
High-quality AI training data is the basis of effective parameter estimation and loss minimization during the machine learning process. To learn from complex patterns and observations, the models adjust their internal parameters so that they are not picking up just the examples, but can accurately identify the underlying structure of data distribution as well.
The model’s ability to perform better on unseen data is thus directly dependent on the quality of training data that it uses to learn.
Machine learning model training data guides the learning algorithm by defining its hypothesis space and providing examples of the important patterns to be learned. The direct relationship between data quality and model capacity is crucial, as models inherit the limitations, biases, and errors of the datasets they are trained on.
The following are some aspects of quality in AI training data:
- Accuracy: Correct and precise values of labels and features
- Consistency: Uniformity of values and standards throughout the dataset
- Completeness: Inclusion of all relevant scenarios
- Representativeness: Data distribution is comprehensively mapped with diverse real-world conditions
Though more data in general helps the model in complex scenarios, it has crucial trade-offs. A small, high-quality dataset delivers better results than a larger one with errors, especially in domains where accuracy is a priority over quantity. AI professionals engaged in developing machine learning datasets need to carefully balance quality against quantity.
Different types of AI training data
AI training data can be categorized based on learning methods, format and structure, and source and collection techniques.
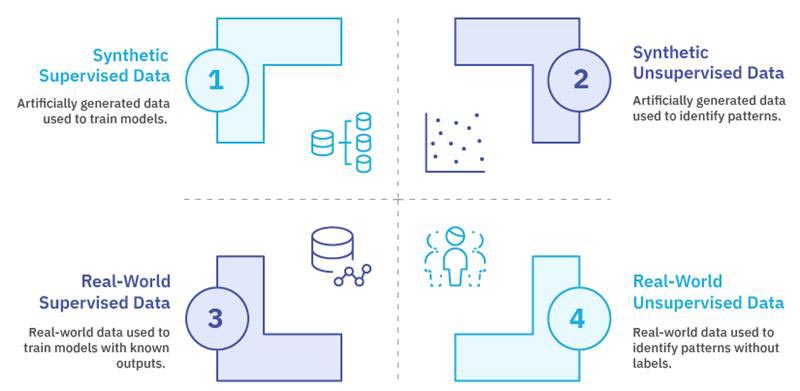
Categorization by learning supervision
Machine learning training data varies greatly based on learning methods. Supervised learning requires labeled data, where each input is mapped correctly to the proper output. This makes error calculation easier. Unsupervised learning uses unlabeled data so that the algorithms can learn to identify patterns and structures by themselves without any guidance.
Weak supervision takes the middle path where limited, noisy, or higher-level labels provide guidance to an extent without requiring precision like that in supervised learning.
Reinforcement learning is another instance where interaction data covers agent–environment exchanges. These datasets contain actions, resultant states, and associated rewards or penalties.
Data types by format and structure
Datasets come in various formats that influence the training process. The following table lists the major data formats, their features and their use cases:
| Data Structure | Features | Examples | Use Cases |
|---|---|---|---|
| Structured | Organized in specific fields, searchable | Databases, spreadsheets, CSV files | Financial analysis, customer records |
| Unstructured | Without predefined format, requires dedicated processing | Text documents, images, audio, video | Natural language processing, computer vision |
| Semi-structured | Lacks standard structure but has tags or markers | JSON, XML, graph data | Web data, knowledge graphs, networked information |
Categorization by source and acquisition method
The origins and methods of collecting artificial intelligence training data are varied. Organic data is created naturally during system operations or human interactions or exchanges that are logged. Curated data is strategically acquired through surveys, experiments, or targeted campaigns for specific learning objectives and designed to addressing specific issues.
Synthetic AI training data is artificially generated through algorithm simulation or rule-based systems to complement real-world samples. Annotated data contains human-made or machine-made automated labels, tags, or categories that help convert raw data into supervised learning materials.
Every source and acquisition method of data varies from each other in scalability, authenticity and bias management. It is thus a crucial consideration during the preparation of datasets for machine learning.
Access diverse and reliable AI training datasets.
End-to-end data collection done by experts.
Key challenges in training data management
Organizations often face challenges while managing AI training datasets that affect model creation timelines and outcomes. Mitigating these challenges that exist throughout the data lifecycle while implementing machine learning requires thoughtful planning, detailed strategies and faithful implementation.
The following challenges are often faced in training data management:
- Accusation and annotation of data requires extensive resources, especially in domains involving expert knowledge.
- As datasets grow to production size, the difficulty in preserving its quality, consistency and representativeness also increases.
- As data grows, the risk of complex forms of data bias getting into the model behavior increases.
- Protecting data privacy and ensuring its security becomes complex as data is scaled. Strict compliance with GDPR and HIPAA becomes a necessity.
- Developing complex machine learning data pipelines that can simultaneously handle both varied data types and volumes.
- Representing and including a wide range of real-world complexities in finite sets of data for AI training in the form of samples of possible situations.
Collecting and annotating data for AI training datasets
Implementing clear strategies while collecting and annotating data is essential for creating accurate datasets for high-performing ML models.
Data collection methods for accurate AI datasets
The methods used for effective machine learning data collection depend on the types of data required for creating the training dataset. Web scraping extracts data from online sources, database queries are helpful in accessing structured data, and targeted campaigns simplify acquiring domain-specific data. There are also public datasets that serve as pre-assembled data for common tasks.
Each data modality has its own challenges. For example, image data requires varied visual conditions, text data requires lingual diversity, and sensor data requires a proper sampling rate and calibration. Active learning processes identify and mark the most informative samples for annotation. This helps optimize the AI training process by prioritizing examples that can maximize learning.
Best annotation practices for AI training datasets
High quality training data for machine learning depends on high-precision annotation processes. Here are some best practices used for data annotation:
- Detailed guidelines: Create very clear, specific, unambiguous annotation guidelines that do not leave much room for interpretation.
- Iterative refinement: Continuously refine the guidelines on annotator feedback and the fresh edge cases encountered along the way.
- Quality control mechanisms: Use consensus requirements, gold standard comparisons, statistical anomaly detection, and other QC methods for extensive verification.
- Edge case management: Set up clear processes for managing ambiguous examples and explicit exclusion criteria.
- Cross functional communication: Establish open communication between annotation teams and model developers.
- Feedback integration: Create a way to feed the learning from the model performance into the annotation process.
- Consistency monitoring: Use inter-annotator agreement metrics to track and single out areas requiring clarification.
- Documentation: Document all annotation decisions, versions, and logic.
Scale annotation projects without sacrificing quality.
Choose custom labeling solutions for your AI development needs.
Preparing data for model ingestion
For successful model ingestion, AI training data must undergo strategic pre-processing, accurate cleaning and thoughtful feature engineering.
Essential data preprocessing
Systematic data preprocessing addresses common challenges encountered while preparing quality AI datasets. To handle missing data, while protecting dataset integrity, techniques like imputation (estimating values) or targeted removal are used. Extreme samples that can impair learning are traced and identified and then handled using techniques like outlier detection.
Data transformation uses appropriate learning algorithms. For example, normalization rescales the values to a defined scale while standardization creates zero-mean-unit-variance distributions. Other scaling strategies resolve skewed distributions. Categorical variables need to be encoded in numerical formats using one-hot encoding or embedding.
Every data modality requires dedicated and specialized pre-processing. While texts need tokenization and vectorization, images require resizing and normalization. Other data like audio depends on spectrogram or other representations for successful feature extraction.
Data cleaning
Robust data cleaning improves machine learning efficiency by getting rid of the errors that affect the model’s understanding and ultimately its performance. This helps in finding duplicate entries and formatting issues, and in correcting contradictions.
It creates a solid and reliable basis for further analysis and feature engineering so that models can clearly identify signals from noise.
Feature engineering
Feature engineering converts raw data into more meaningful and informative features that help boost machine learning model performance by detecting relevant patterns. Using mathematical transformations, aggregations or domain specific techniques, new values are derived that clearly highlight the vital differences in information.
For some tasks, deep learning has reduced the need for manual feature engineering as neural networks can learn important representations directly from raw data. However, for structured data problems, thoughtful feature engineering remains valuable. In such cases, domain-specific knowledge can be used to easily identify meaningful patterns in machine learning datasets.
Video annotation for smart city traffic analytics

A California-based data analytics company wanted to create a machine learning model capable of analyzing live and recorded traffic footage to improve traffic conditions in the city. To prepare the training data, they needed to label millions of video frames for accurate vehicle detection, movement tracking and fruitful traffic analysis.
HitechDigital annotated a large quantity of traffic footage and categorized vehicle and pedestrian types, directions and movement patterns. A team of experts overcame challenges like varying lighting, weather conditions and complex backgrounds to deliver high-quality training data.
The final deliverable led to:
- Real-time traffic dashboard with directional volume insights
- Better queue and stationary vehicle detection
- Improved traffic planning and congestion prediction
Expanding datasets with synthetic data and augmentation
Real world data has availability and privacy constraints. To overcome these limitations and train models better, datasets are artificially expanded with the help of synthetic generation and augmentation.
Synthetic AI training data
Artificial examples that complement real-world data are created using technical processes to populate synthetic AI training datasets. Generative adversarial networks (GANs) train competitive networks to create realistic synthetic samples.
Simulation environments use known rules to generate examples by modeling physical or logical systems. Rule-based approaches directly encode domain knowledge within data generation processes.
In comparison to real data, synthetic data is advantageous for generating and representing rare cases since there are no associated issues of distribution control or privacy concerns. However, it involves the risks of lack of alignment to real world scenarios and can introduce biases and systematic artifacts into the learning process, unless the synthetic data generation is closely supervised.
Data augmentation
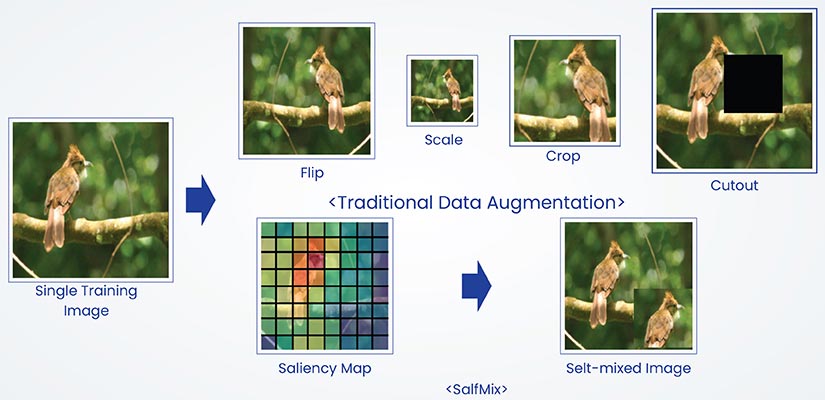
Data augmentation is the process of transforming and adding to existing data in a way so that controlled variations can be introduced in the dataset while preserving the fundamental essence of the data.
For image data, common techniques used are rotation, flip, color shifts and elastic distortions. For text data, synonyms, paraphrasing and back translation are used. Audio data augmentation uses time stretch, pitch shift and noise addition.
Through this process, the models are exposed to variations that help improve generalization during deployment. Augmentation is particularly useful in class imbalance or data scarcity, as it creates probable variations without collecting any new data. These transformations help reflect real-world variability without introducing unrealistic errors into the datasets.
How to handle ethical risks and bias in training data
Historical patterns of data, collection methods, or errors during the annotation process can introduce algorithmic bias in machine learning datasets. When trained on these biased examples, models internalize these flawed patterns, amplify them and ultimately produce unfair and erroneous outcomes.
For example, face recognition systems trained on certain demographic groups can perform poorly on underrepresented groups. Similarly, natural language models can retain gender stereotypes from training data, and recommendation systems may learn to impose societal disparities when trained on historical interaction data.
The following are some of the ways to avoid and mitigate bias in data:
- Prepare balanced samples covering sensitive attributes uniformly
- Reweighing examples for equal representation
- Ensuring explicit penalization of discriminatory patterns using adversarial networks
- Setting strict constraints for fairness in the learning objective
Data privacy regulations like GDPR and HIPAA necessitate addressing a greater number of requirements in AI data training. These frameworks mandate informed consent, purpose limitations and data minimization principles that fundamentally dictate how organizations can collect and use training datasets.
Responsible data governance ensures transparency throughout the data lifecycle – from acquisition to annotation and model training. The dataset compositions, limitations and use cases need to be documented under data governance to ensure their proper application and accountability.
Conclusion
The quality, quantity and representativeness of AI training data determines the abilities of machine learning. Designing, managing, and maintaining training data are extremely crucial for building successful AI systems.
Understanding training data complexities at different stages—from data collection and annotation to preprocessing and augmentation—is all part of laying the foundation for responsible AI. Data scientists and ML teams must recognize the importance of training data as the fundamental basis for machine learning. It must be reviewed regularly, versioned systematically, and audited like code.
By following these practices, AI professionals can build accurate, helpful AI systems that are fair, adaptable, and future-proof.
Generate training data without real-world risks.
Scale your dataset affordably with synthetic data.




