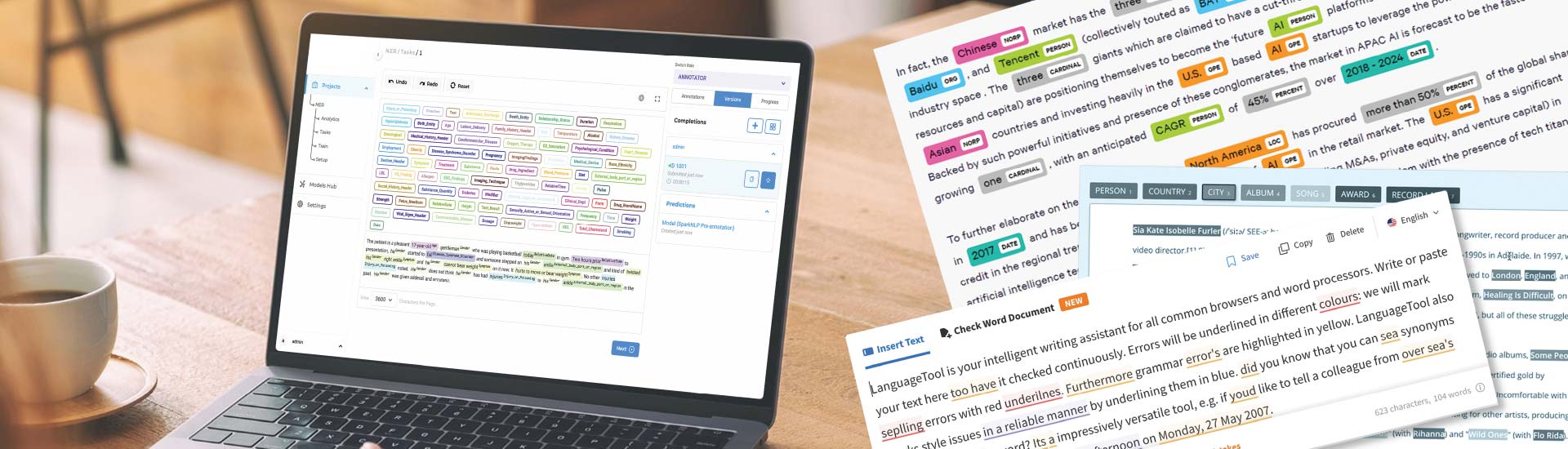

- NLP may empower intelligent systems; however model accuracy relies on high-quality training data built using accurate text annotation.
- For resolving ambiguity, domain complexity, and real-world noise to get reliable machine understanding; text annotation is used to transform unstructured language into structured datasets.
- Professional annotation solutions ensure your NLP systems are accurate, scalable, bias-mitigated, and production-ready AI systems across diverse industries.
Table of Contents
- What are different types of text annotation used in NLP
- Why text annotation is key to accurate NLP models
- How poor text annotation impacts model accuracy and performance
- Domain-Specific text annotation and its applications
- What are the challenges and best practices in text annotation for NLP
- Evolving Techniques in Text Annotation
- Why outsource text annotation services
- Conclusion
Natural Language Processing (NLP) is what modern AI systems thrive on. It can be virtual assistants, recommendation engines, fraud detection platforms or legal automation tools; NLP empowers machines to understand, interpret, and act on human language. The advancement in deep learning and large language models is immense and fast paced, but the fact that remains unchanged – NLP models are only as good as the data used to train them. This makes text annotation foundational.
Text annotation in machine learning transforms raw, unstructured language data into structured and labeled training datasets. It bridges the gap between machine comprehension and human-language. Incomplete or inconsistent text annotation leads to ambiguity, domain complexity, and real-world noise and make your advanced NLP architecture to fail miserably.
So, now that we know that text annotation is critical for NLP models, let’s find out why text annotation is essential for building accurate NLP models, how it improves performance across industries, and why professional annotation services are a strategic necessity for AI-driven organizations.
What are different types of text annotation used for NLP models?
Text annotation assigns meaningful labels to language data. It empowers supervised learning algorithms to classify information and identify patterns to make accurate predictions. Annotations are embedded in the NLP lifecycle for data preparation, model training, evaluation and for refining prompts. Advanced NLP systems leverage several annotation techniques, each of which helps to capture specific language aspect.
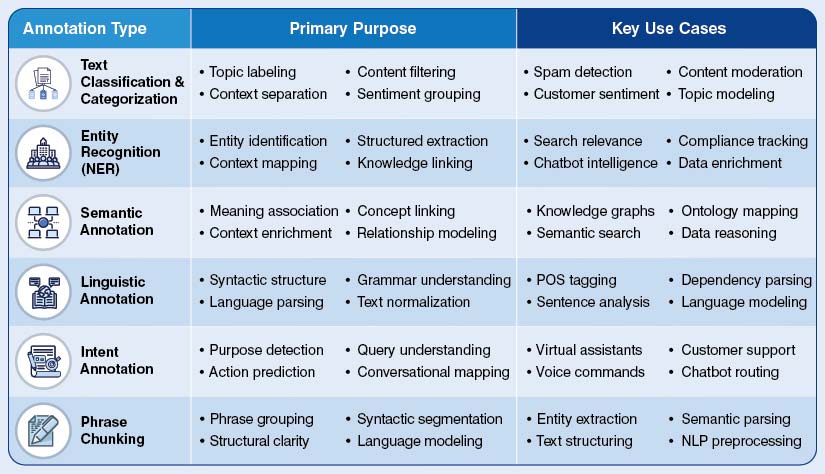
All the above mentioned annotation methods are used to train the NLP model to understand syntax, semantics and intent of the language.
Why text annotation is key to accurate NLP models?
Basic understanding is that without text annotation or labeled text, any AI or ML model will see text as a random string of characters and with them the model will perceive intent, sentiment, and structure too. Here’s why text annotation is key to accurate and high-performing NLP models.
Training contextual intelligence
As we all know, computers don’t understand human nuance, sarcasm, or domain-specific jargons. Text annotation provides the ground truth that helps AI and ML model to learn how to interpret context. For example, the statement “The crane was moved to the construction site” will raise ambiguity in the model. Accurately annotated text will empower your model to understand the difference between a bird and machinery.
Enables extraction of precise information
Named Entity Recognition (NER) technique is used to help the AI and ML models to pull out specific data points:
- Healthcare: Extract symptoms of the disease, dosage of medicine, and names of patients from clinical notes.
- Legal & Compliance: To identify and classify clauses, dates, and parties from legal contracts.
- Finance: Monitoring market sentiments by tagging specific ticker symbols and financial events.
Improving model accuracy and reducing bias
The performance of any NLP model is directly proportionate to the quality of training dataset that is used to train the model. High-quality, human-verified annotations:
- Minimize Noise: Ensure the model is not learning from incorrect or irrelevant data.
- Edge Cases: Automated systems may miss out on recognizing some language patterns that human annotators label accurately.
- Mitigate Bias: Text annotators identify and label biased language to stop the model from learning harmful stereotypes.
Real-world environments
AI interactions depend heavily on specific types of text annotations:
- Sentiment Analysis: Tracking customer satisfaction using social media.
- Intent Labeling: Help Alexa and Siri to categorize user’s command, question, or greeting.
- Machine Translation: Parallel corpora to maintain grammatical and cultural accuracy.
How poor text annotation impacts NLP model accuracy and performance
Garbage in – garbage out remains to be the thumb rule for NLP development as well. Machine learning models mirror their training data and hence the quality of text annotation and labeling serves as the benchmark for a model’s performance. Poor annotation does not just lead to minor hiccups, but it creates a fundamental glitch that leads to systematic failure across accuracy, reliability, and user trust.
Misclassification and Hallucination
Poor annotation is a villain for large language models (LLMs) and delivers hallucinations. Weak or contradictory underlying semantic relationships in the training set, confidently generate factually incorrect or nonsensical outputs to fill the gap in its understanding. You cannot expect a bigger disaster than this.
- Incorrect entity annotation in a retail environment will make the model fail at distinguishing between “Apple” the brand and “apple” the fruit. It will lead to faulty recommendation engines that frustrate users with irrelevant products.
- Ambiguous intent tagging in conversational AI will make the chatbot misinterpret user goals; so, if a user says, “cancel my order” the model trained on inconsistent labels may categorize it as a “general query” and end up sending a circular or creating an unhelpful conversation that will frustrate the user.
The only way to deal with the above issues is to consider text annotation and labeling as an engineering task which requires utmost precision:
May it be legal, medical, or technical text labeling, annotators should identify and label nuances that a generalist might miss out on.
- Domain Expertise: May it be legal, medical, or technical text labeling, annotators should identify and label nuances that a generalist might miss out on.
- Inter-Annotator Agreement (IAA): Leverage Cohen’s Kappa or Fleiss’ Kappa to find out how human annotators agree on labeling a particular text. If the annotators understand the annotation guidelines thoroughly the IAA scores will be high.
- Human-in-the-Loop – HITL: Human in the loop systems are the best for continuous validations. It enables you to route back low-confidence predictions back to human experts for verification.
High-quality annotated training datasets are more than just labeling. Text annotation is about building a strong foundation for NLP algorithms and AI models to make them predictable and trustworthy.
Domain specific text annotation and its applications
Diverse industries use and generate a wide range of language data. Domain specific text annotation confirms that NLP systems interpret languages adhering to contextual and regulatory frameworks.
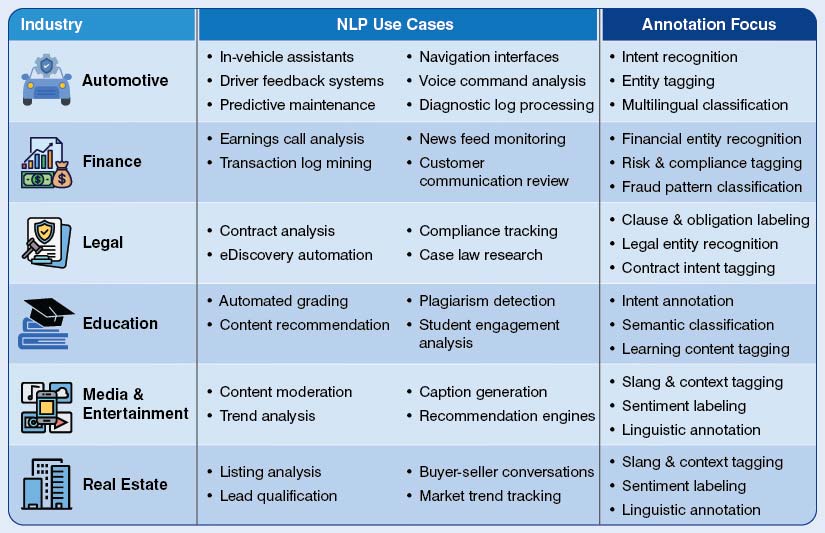
What are the challenges and best practices in text annotation for NLP?
The complexity of annotating and labeling text increases manifold due to fluid and subjective human language. Linguistic ambiguity increases due to multiple meanings of a single word because of cultural context, sarcasm, or industry-specific jargon.
Maintaining inter-annotator consistency as defined in text annotation quality metrics adds significant reliability to NLP training datasets. It warrants a shared mental model. Two individual annotators may end up labeling the same sentence differently, leading to noisy training datasets. It could derail a machine learning model’s training schedule. Here are text annotation best practices that help organizations to overcome these challenges:
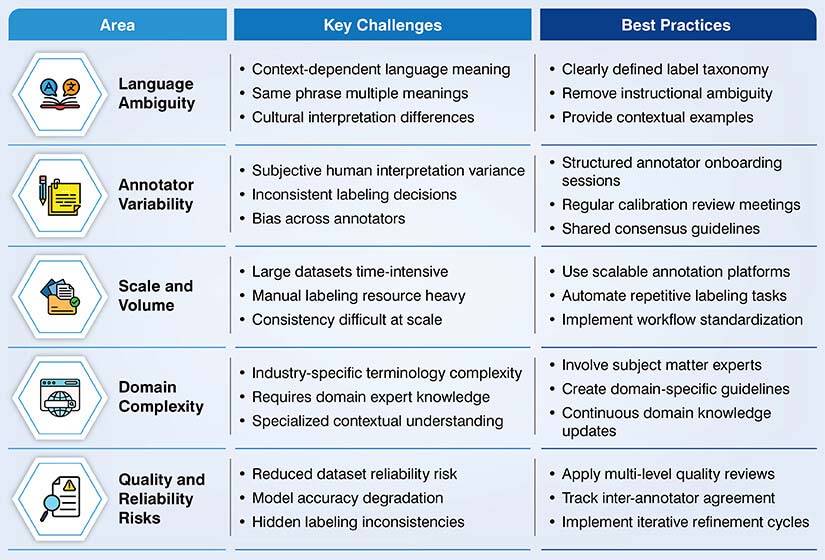
Human-in-the-loop approach was and will always be non-negotiable, even with all the advancements in automated text annotation tools. Humans are irreplaceable when it comes to navigating rare, complex linguistic structures with insufficient representation in existing datasets. We call them “edge cases”. Human intuition fuels the nuanced understanding required to decide subjective interpretations, which algorithmic approaches always tend to miss. This ensures that the model’s output remains grounded in reality.
Evolving techniques of annotating text for NLP models
Text annotation has evolved from purely manual processes to hybrid systems combining automation and human validation.
- Semi-automated annotation: Human annotators verify and correct outputs, whereas AI backed tools pre-label data. This combination fast tracks throughput while keeping the quality consistent.
- Active learning: Prioritizing unclear samples for annotation reduces labeling efforts and enhances model performance.
- Ontology-driven annotation: Domain ontologies and knowledge graphs are critical for semantic annotation as they improve contextual representation.
Labeled data is more important than zero-shot and few-shot learning as they are critical for grounding models and reliability.
Why outsource text annotation services for NLP models?
The journey of outsourced text annotation, from a simple cost-saving measure to a strategic necessity, has evolved like anything. And why not? It addresses the challenge of the massive volume of high-quality, labeled data required to move from prototype to production, which is the primary bottleneck in NLP development.
Key Strategic Advantages of outsourced text annotation / Key Advantages of outsourced text annotation
- Operational efficiency: Outsourcing text annotation projects addresses the issue of managing in-house annotation teams which is a resource intensive task. It also frees your high-paid data scientists from labeling tasks and allowing them to pay due attention to model architecture, innovation, and refinement.
- Rapid scalability: Fluctuating demand for training datasets pose a different challenge for AI projects. Text annotation service providers are equipped with manpower to scale up the workforce instantly for large datasets or seasonal spikes. It eliminates the delays of internal hiring and training.
- Access to expertise: Specialized text annotation solutions providers facilitate domain-trained annotators for projects across automative, retail, real estate, legal, medical, financial and many more. They leverage quality assurance frameworks like Inter-Annotator Agreement (IAA) metrics for a level of precision and consistency that is difficult to maintain with a generalist in-house team.
- Accelerated time-to-market: Outsourcing partners are equipped with established workflows and pretrained annotators onboard to deliver accurate annotated training datasets 5 times faster compared to in-house teams. This works in your favor to deploy your AI solutions faster than competitors.
Conclusion
Accurately annotated text is the cornerstone for production-ready NLP systems. High-quality domain specific text labeling is not optional. It is the ground truth that takes care of accuracy, eliminates bias and prevents model hallucinations.
The demand for sophisticated, context-aware AI models is increasing across industries, making the need to partner with text annotation expert service providers a prime necessity. It also helps you to maintain a competitive edge in the modern linguistic landscape.




