

- Text annotation in machine learning turns unstructured language into structured training data so models can see patterns, understand context, and make predictions.
- High-quality annotation determines model performance and helps create reliable systems across the healthcare, finance, legal, retail, and customer service sectors.
- Effective annotation strategies including human-in-the-loop, clear guidelines, and quality control help overcome ambiguity, consistency, and resource constraints.
Table of Contents
- Importance of text annotation in machine learning
- Turns unstructured text into usable training data
- Provides high-quality labeled data for supervised learning
- Supports complex NLP tasks and deep language understanding
- Enhances model transparency and interpretability
- Drives accurate and reliable predictions
- Enables continuous learning and adaptability
- Text annotation types driving different NLP outcomes
- Common challenges impacting text annotation for ML
- Strategies to ensure effective text annotation in machine learning
- Application of text annotation in training ML across industries
- Conclusion
Machine learning models need structured, labeled data for accurate comprehension and learning. Unstructured text with ambiguities and complexities confuses model training, as algorithms cannot extract meaningful patterns from such raw text.
The use of text annotation in machine learning bridges this gap by transforming unprocessed information into logically labeled datasets that algorithms can understand. By identifying, categorizing, and marking textual elements according to their attributes, annotation provides the foundation for natural language processing systems. Annotations guide models to detect patterns and understand context.
In this article, we discuss how high-quality text annotation improves model accuracy, generalization and nuanced language understanding. We also take a look at text annotation strategies that directly improve AI system performance and reliability. It may be in processing customer feedback, analyzing documents or automating communication in real-world applications.
Importance of text annotation in effective machine learning
Accurate text annotation is the foundation of quality machine learning training data. This process gives you the following six key capabilities that help drive NLP systems.
Turns unstructured text into usable training data
Raw text is just a collection of characters and words with no meaning or relationships for algorithms to work with. We use text annotation in machine learning to convert this raw unstructured text into structured formats that models can learn from.
Through annotation, text is categorized and contextualized, with important bits tagged according to function, meaning or relevance. This structuring reduces the complexity of natural language, making information actionable for machine learning algorithms. The annotation process is like a translation layer between human understanding and machine-readable data.
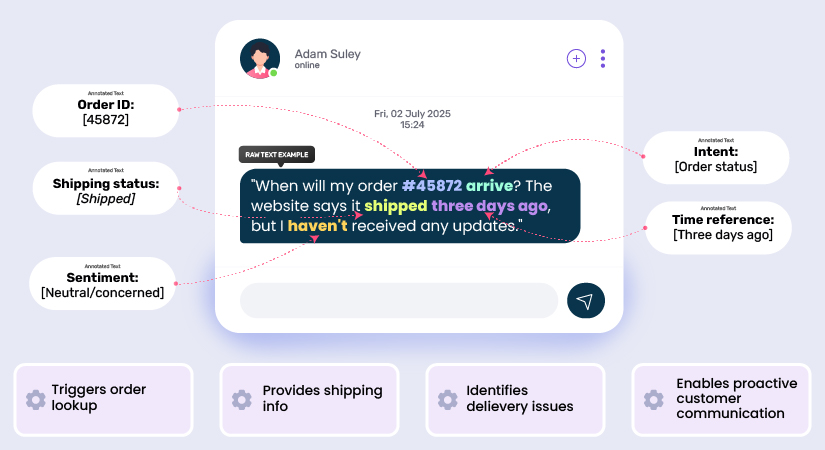
Provides high-quality labeled data for supervised learning
Supervised learning algorithms rely on accurately annotated data to recognize patterns and make predictions. The quality of text labeling for NLP determines the model performance in the real world.
With proper text annotation, supervised learning achieves the following:
- Precise distinction between similar expressions with different meanings
- Accurate interpretation of contextual variations and nuances
- Focus on meaningful linguistic patterns rather than superficial features
- Strong generalization beyond training examples
- Mitigation of biases in raw, unlabeled data
Consider the following example of a contract analysis system evaluating the statement, “The party shall not be obligated to fulfill section 3.2 requirements.” Without proper annotation, the model might miss negation and misclassify this as an obligation rather than an exemption. Proper annotation of negation patterns prevents such mistakes.
TRAINING PHASE:
- Input: “The party shall not be obligated to fulfill Section 3.2 requirements.””
Annotation process
Correct label: [EXEMPTION]
Model training
Learning: Pattern “shall not be obligated” means EXEMPTION
DEPLOYMENT PHASE:
- New input: “The vendor shall not be required to provide maintenance…”
-
Model application
Output: EXEMPTION (Correct classification)
Supports complex NLP tasks and deep language understanding
NLP goes far beyond simple classification tasks; it includes complex challenges that require deep language understanding. Text annotation makes these advanced capabilities possible by providing the detailed context that models need to develop language-processing abilities.
Sentiment analysis requires annotation that captures not just positive or negative polarity but degrees of sentiment, implied attitudes, and contextual factors that change meaning. Intent detection requires annotation that distinguishes between subtle variations in user requests or commands.
For example, an email response system can understand “Where’s my refund for order #A12345?” as a tracking request with neutral tone versus “Still waiting for my refund!” as urgent with negative sentiment—so it can prioritize accordingly.
Through detailed annotation schemas that capture linguistic nuances, developers create training data that enables models to understand context, recognize implications and interpret meaning beyond the surface text. This is what separates basic keyword-matching systems from NLP applications that can have meaningful human-computer interaction.
Sentiment annotation for customer email analytics

A global digital services provider wanted to build a machine learning model to analyze customer sentiment from emails every 12 hours. They were struggling to aggregate emails from multiple inboxes, interpret different expressions, and tag sentiments for training data.
HitechDigital manually annotated thousands of emails, categorizing them by sentiment and subcategories. This structured data was used as input for the client’s ML algorithm to perform real-time sentiment analysis and improve customer experience.
The final deliverables led to the following:
- A training dataset for ML-based sentiment analysis
- Improved customer journey insights
- Proactive issue resolution through sentiment detection
Enhances model transparency and interpretability
Well-documented text annotation schemas provide visibility into the reasoning behind model predictions so developers and users can understand why specific decisions are made.
By tracing model outputs back to the annotated examples that influenced its learning, stakeholders can identify biases, understand limitations and build trust in the system’s capabilities. This is crucial in regulated industries, where explainability is a requirement.
Text annotation that follows guidelines and methodologies provides compliance with the latest AI regulations. As frameworks like the EU’s AI Act and industry-specific regulations evolve, being able to demonstrate responsible data practices – including thorough, unbiased annotation – is a competitive necessity.
Train your AI models with labeled text data
Get data clean and categorized for ML workflows
Drives accurate and reliable predictions
Text annotation provides the ground truth against which models calibrate their internal parameters during training. The generalization capability of models—their ability to perform well on new data beyond their training examples—depends heavily on exposure to diverse, well-annotated examples.
By including different language patterns, edge cases, and potential ambiguities in the annotation process, developers can build models that work successfully across different contexts and user populations.
Consider this example:
Raw text:
Please cancel my flight reservation for tomorrow and book it for next Friday.
Annotated text:
[Intent: Change Reservation]
[Action: Cancel, Object: “flight reservation”, Time: “tomorrow”]
[Action: Book, Object: “flight reservation”, Time: “next Friday”]
Impact on prediction reliability:
When a properly annotated example is added to the training data for a travel booking assistant, the model learns to identify both the cancel and book actions in a single request.
So, in production when a customer writes “Need to move my Tuesday flight to Saturday,” the model will predict this as a change request that requires both cancel and book actions—not just cancel or info request.
Enables continuous learning and adaptability
Language is dynamic and keeps constantly changing with new terms, new usage patterns, and shifting cultural contexts. Text annotation enables the continuous learning necessary for models to stay relevant in this changing environment.
Ongoing annotation of new data allows organizations to update their models to recognize new terminology, adapt to changing communication styles, and maintain performance as user needs change. This continuous improvement cycle relies on annotation infrastructure and processes that can scale with growing data and changing requirements.
Adaptability enabled by text annotation goes beyond vocabulary updates to fundamental changes in language patterns.
For example, the rapid evolution of social media communication requires models to understand new abbreviations, emoji usage, and context-specific meanings that didn’t exist during training. Only through continued text annotation can models navigate these changes.
Text annotation types driving different NLP outcomes
Different annotation types enable different NLP capabilities, each for specific use cases and applications. Knowing these text annotation in NLP helps you choose the right annotation strategy for your machine learning goals.
Named Entity Recognition (NER)
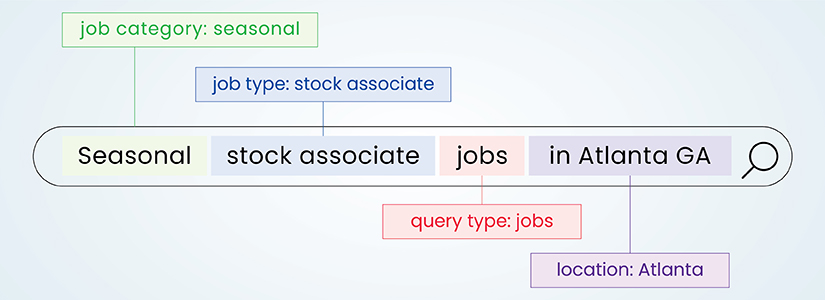
NER annotation identifies and categorizes entities (people, organizations, locations, and dates) in text. This allows information extraction systems to extract specific entities from unstructured documents.
For example, in “The Department of Energy reported a 15% increase in renewable installations across 12 states during Q2 2024,” proper NER annotation would identify “Department of Energy” as organization, “15%” as percentage, “12” as cardinal number, and “Q2 2024” as powering applications from energy policy analysis to environmental impact assessment and compliance monitoring.
Extract names, places & more with entity annotation
Build smarter NLP with named entity tagging
Part-of-Speech (POS) tagging
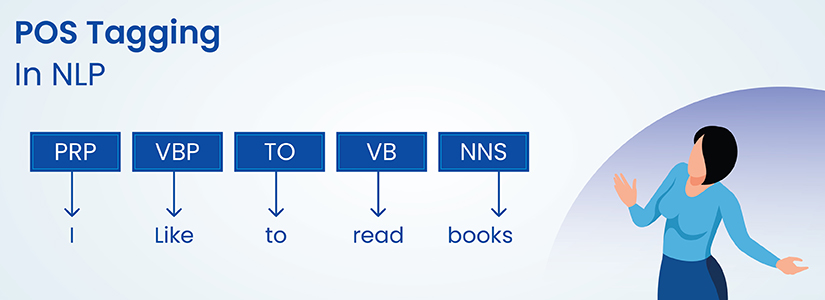
POS tagging assigns grammatical categories to words and provides syntactic information for language understanding. This basic text annotation in NLP technique helps models distinguish between same words with different functions—like “book” as noun versus verb.
Advanced POS annotation includes tense and case information, supporting complex parsing operations that underpin machine translation and grammar-checking systems.
Sentiment annotation

Sentiment annotation adds emotional tone indicators to text, from positive to negative, with varying degrees. Sentiment classification dataset labeling often captures emotions toward specific targets—a single review might be positive about price but negative about durability.
These text annotations train customer sentiment analysis systems that monitor brand perception, track customer satisfaction, and identify what drives reactions to products or services. Discover a structured text annotation process for sentiment analysis that improves model accuracy and customer insights.
Intent annotation
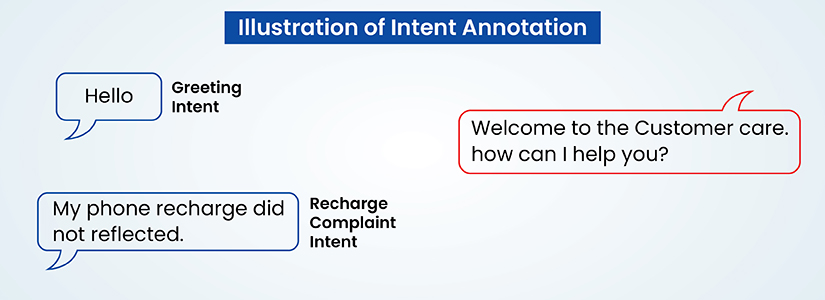
Intent annotation identifies the underlying purpose in the text, categorizing utterances by their goals. This involves labeling text for classification tasks, such as “schedule appointment” or “request information”.
Intent-annotated training data allows conversational AI systems to know what users want to do, so virtual assistants can route requests and respond accordingly without needing rigid command structures.
Entity linking
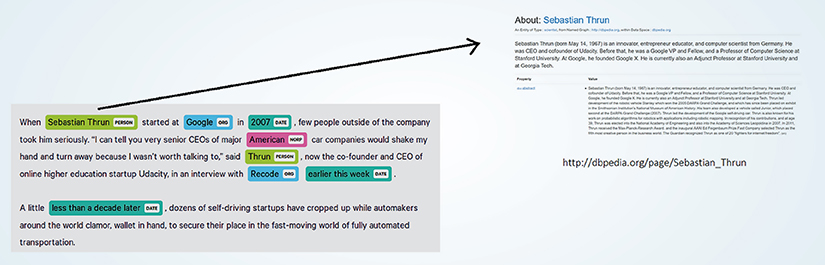
Entity linking annotation links text mentions to specific knowledge base entries, and in the process resolves ambiguity by making precise references. Unlike basic NER, entity linking distinguishes between “Apple” as the company, the fruit, or other entities based on context.
These annotations train systems that enable advanced information retrieval, fact-checking applications, and knowledge graph construction for academic research and commercial use.
Common challenges impacting text annotation for ML
Despite its importance, several text annotation challenges impact machine learning model quality:
- Linguistic ambiguity and context: Language is often imprecise and can have multiple interpretations based on context, cultural references, and usage patterns.
- Inconsistent annotation: Annotators might apply different standards to the same phenomena, creating noisy data that hurts model performance.
- Resource constraints: Manual annotation is time-consuming and expensive, so there is often a compromise between thoroughness and speed, especially with large volumes of text.
- Interpretive subjectivity: Annotators disagree on sentiment and intent, creating inconsistencies that propagate to model behavior.
- Specialized knowledge gaps: A lack of domain experts hinders annotations in specialized fields that require technical terminology understanding.
- Privacy concerns: Organizations struggle to balance annotation with data protection when dealing with sensitive information.
Strategies to ensure effective text annotation in machine learning
Overcoming challenges in text annotation is key to building generalizable and reliable machine learning models. The following strategies ensure that your annotation practices directly improve model performance and resilience across all NLP tasks.
-
Human-in-the-loop text annotation frameworks
Integrate human judgment at key decision points to resolve ambiguity, capture subtle context shifts, and validate edge cases. Subject matter experts (SMEs) are crucial in domains like legal, medical, or technical annotation to ensure accurate interpretation of specialized language and intent signals that automated tools miss.
-
Utilize active learning and semi-automation
Combine algorithmic prediction with human oversight to annotate the most informative samples. This speeds up dataset development and helps models learn from hard-to-classify instances, improving generalization performance and addressing class imbalance
-
Define detailed, domain-specific annotation guidelines
Create comprehensive documentation with clear instructions, contextual cues and edge case examples. As well-structured guidelines reduce subjectivity and inter-annotator variance, annotations reflect a unified linguistic and conceptual framework aligned with the model’s downstream tasks.
-
Implement layered quality assurance
Incorporate multi-level validation, such as consensus scoring, adjudication rounds, and gold standard benchmarking. Regular audits and inter-annotator agreement metrics keep the dataset clean and improve model outputs.
-
Establish feedback loops between annotators and model performance
Annotate the errors that come from annotation gaps. Use those insights to update guidelines, retrain annotators, or re-label critical examples. In this way, annotation evolves with the model’s needs and emerging trends.
-
Deploy annotation platforms with built-in security and collaboration features
Use professional tools like Labelbox, SuperAnnotate and V7 that streamline workflows, standardize interfaces and enforce quality protocols. Use scalable platforms with role-based access control to manage large teams and protect personally identifiable or confidential data during annotation.
Beyond using tools, applying robust text annotation quality control is key to minimizing errors and improving outcomes.
By following these practices, you can turn text annotation from a bottleneck into a strength that directly feeds into model accuracy, fairness, and robustness.
Application of text annotation in training ML across industries
The benefits of text annotation enable machine learning applications across various sectors for industry-specific solutions and challenges.
Healthcare
Text annotation converts clinical notes, medical literature and patient communications into structured training data for information extraction systems. Annotated medical terminology enables automated EHR population and clinical decision support systems that identify drug interactions – providing better patient care through efficient information use.
Finance and banking
Financial institutions use text annotation services to process regulatory filings, transaction records and customer communications. Annotated financial entities and risk indicators train automated analysis systems to identify fraud patterns, assess credit risk, and monitor compliance across different document types, reducing manual oversight.
Legal
Accurately annotated contracts train systems to identify obligations and conditions automatically. Case law annotation enables research systems to find relevant precedents. Legal document annotation trains categorization systems to streamline knowledge management within organizations.
Retail and e-commerce
Retailers apply text annotation in machine learning to product descriptions and customer reviews. Annotated product attributes train search and categorization systems. Sentiment classification dataset labeling enables customer review analysis to identify specific product aspects that generate positive or negative feedback to drive focused product improvements.
Customer service and support
Applications of text annotation in customer service turn support interactions into training data for virtual assistants. Intent annotation trains chatbots to understand customer requests correctly. Sentiment analysis trained on annotated feedback helps gauge satisfaction and identify emerging issues, while annotated knowledge bases improve self-service resources.
Conclusion
The quality and consistency of text annotation in machine learning have a significant impact on model performance, and that impact will only grow as organizations try to get more value out of unstructured text data.
Looking forward, semi-automated annotation, transfer learning, and domain adaptation will make text annotation more efficient. But contextual understanding, cultural awareness, and nuanced interpretation that human annotators bring—will still be essential in building NLP systems that understand human communication.
So, investing in good text annotation practices—clear guidelines, iterative feedback, and quality control processes—will help you build more capable, accurate, and reliable NLP systems.
Map customer queries to accurate intents easily
Build intelligent bots with annotated intent data




