

- Text annotation is essential for AI and ML companies to accurately identify customer sentiment.
- It helps in identifying the pulse of customer sentiment, capturing the essence of human expression, and converting it into insights.
- Understanding of the process, as described in detail in this article, is key to improving consumer insights and shaping business strategies.
Text annotation for customer sentiment analysis is essential for training AI and ML models. It involves attaching labels, metadata or tags to textual data to indicate the emotional tone conveyed by customer feedback. The quality and accuracy of these annotations are crucial for sentiment analysis algorithms.
Table of Contents
- Text annotation for Sentiment Analysis
- Text Annotation Challenges
- Text annotation types relevant to sentiment analysis
- The Text Annotation Process
- Quality Control in Text Annotation
- Training and Evaluation of Annotators – A Prerequisite
- Points to consider while selecting text annotation tools
- AI-Driven Text Annotation Tools
- Real world use cases
- Conclusion
For AI and ML companies, understanding and implementing text annotation is a strategic necessity. Inaccurate data labeling can result in flawed sentiment analysis, leading to misunderstandings of customer feedback. This can have serious consequences, such as poor customer experience management and misguided strategic
Therefore, it is essential for these companies to have a strong knowledge of text annotation to ensure accurate sentiment analysis, which is crucial improving customer experiences.
This article will give you a detailed understanding of the text annotation process, the associated challenges, how to overcome them, and finally how to leverage sentiment analysis using text annotation for strategic planning and better decision making.
Text annotation for Sentiment Analysis
The process of text annotation starts with collecting a body of text, often customer reviews or feedback, which is then carefully reviewed by human annotators or automated systems.
In machine learning and natural language processing (NLP), text annotation serves as a way to create training data that helps algorithms learn to recognize patterns and make decisions based on them.
This data should be of high quality for maintaining the reliability and validity of sentiment analysis data using AI and ML. You can read in detail about the benefits of high-quality data annotation here.
Annotation techniques range from basic sentiment classification (positive/negative) to detailed multi-class labeling (like happy, sad, angry). The process involves tokenizing raw text into smaller units (words, phrases) and assigning sentiment scores to each.
These annotated texts are then used to train predictive models using semantic rule-based systems or machine learning algorithms. The data is typically structured in a table format for easier model training and evaluation.
| Text Sample | Annotated Sentiment | Sentiment Score |
|---|---|---|
| Impressed with the fast service! | Positive | 0.9 |
| Waited too long for a simple order. Not happy. | Negative | 0.6 |
| Decent food but the ambiance lacks warmth. | Neutral | 0.1 |
Text Annotation Challenges
Sentiment analysis in human language faces challenges due to subjectivity and ambiguity. Key focus areas include:
- Subjectivity and Ambiguity: Varied emotion interpretations lead to inconsistent data labeling. Clear guidelines are needed for accurate analysis, especially with ambiguous customer feedback.
- Tone Detection: Identifying tone involves understanding emotions, cultural expressions, and nuances. Recognizing sarcasm and subtle emotion differences is crucial.
- Polarity and Mid-Polarity Phrases: Differentiating positive and negative sentiments is complicated by phrases that blend both. Context and cultural nuances are vital for correct classification.
- Sarcasm and Irony: These elements change the intended meaning and require analysis of contextual clues, punctuation, and cultural references.
- Idioms and Figurative Language: Customer feedback often includes idioms, which need accurate interpretation to understand true sentiments.
- Negations and Double Negatives: These alter sentiment and require careful context interpretation, language nuances recognition, and algorithm training.
- Comparative Sentences: Analyzing context-dependent sentiments in comparisons demands in-depth language and product knowledge.
Text annotation types relevant to sentiment analysis
In sentiment analysis, among the various text annotation types, the following are particularly relevant:
Sentiment Annotation
 Sentiment Annotation
Sentiment Annotation
This process involves labeling text with the emotions, attitudes, and opinions it expresses. Three primary text annotation types used in sentiment analysis are categorical, scale-based, and aspect-based annotations.
- Categorical Annotation: Assigns predefined sentiment categories.
- Scale-Based Annotation: Rates sentiments on a numerical scale.
- Aspect-Based Annotation: Focuses on specific aspects of entities.
Intent Annotation
 Illustration of Intent Annotation
Illustration of Intent Annotation
Intent annotation focuses on uncovering the underlying intent in customer interactions which denotes the purpose of the text, such as seeking information or expressing a preference. It involves labeling text data that indicates intent behind words and categorizing them as positive, negative, or neutral.
Semantic Annotation
 Semantic Annotation
Semantic Annotation
This involves tagging text with metadata that describe concepts like people, places, organizations, products, or topics relevant to the content. Semantic annotation further refines the understanding of customer sentiment by identifying and categorizing subjective information within the text.
Entity Annotation
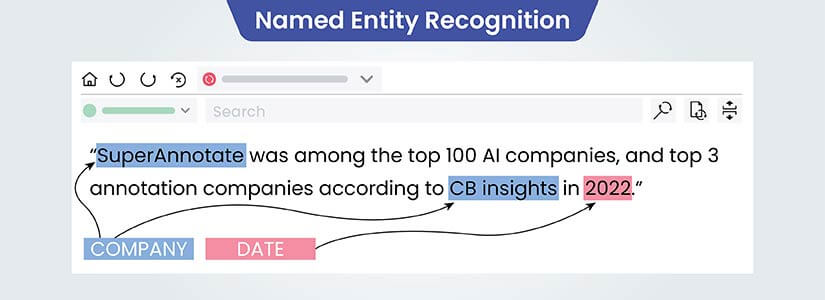 Named Entity Recognition
Named Entity Recognition
Entity linking connects entity mentions in text to corresponding knowledge base entries. This clarifies the specific entities sentiments are directed at, especially when names are ambiguous.
Techniques such as Named Entity Recognition (NER) are commonly used to automate this process. Each identified entity is annotated with tags that indicate its category, which can be predefined in an annotation schema tailored to the business’s needs.
This helps businesses understand how consumers perceive their offerings, informing brand reputation management strategies.
Linguistic Annotation
 Part-of-speech tagging
Part-of-speech tagging
This includes adding notations that describe linguistic features of the text, such as phonetics, grammar, and syntax. Understanding the linguistic context can be important for accurately gauging sentiment.
- Part-of-Speech Tagging: Assigning word classes, like noun, verb, adjective, etc.
- Syntactic Annotation: Analyzing and marking up the sentence structure.
- Pragmatic Analysis: Looking at language use in context, such as speech acts.
- Semantic Role Labeling: Adding information about the meanings of words.
- Discourse Analysis: Understanding how sentences connect and flow in a larger context.
These types are helpful in understanding the context and nuances of customer opinions, leading to more precise sentiment interpretation.

The Future of Data Annotation: Key Trends and Innovations
- Industries globally are impacted by advancements in annotation.
- Smart tools and techniques enhance the performance of ML models.
- Synthetic data and multimodal annotation are trends that will dominate.
- Ethical data annotation practices ensure responsible AI development.
The Text Annotation Process
Text annotation in machine learning is crucial for training AI and ML models, especially in tasks related to natural language processing (NLP). It involves collecting data, preparing the data for annotation, setting up annotation guidelines and adding metadata or labels to raw text data, transforming unstructured data into a machine-readable format. This process allows ML models to understand, interpret, and make predictions based on text inputs, learning and generalizing patterns from the annotated examples.
Following sections will guide you through the detailed process of text annotation.
1. Text Data Collection and Preparation
Initiating the annotation process for natural language processing (NLP) requires collecting a varied and relevant sample of text from sources like public databases, social media, and customer feedback.
Text data can be sourced from digital text, handwritten text (using Optical Character Recognition or OCR), or text in images. Ensuring a broad range of data types is crucial, as it should cover practical use cases relevant to the specific NLP application.
Web scraping offers quick data collection but requires strict adherence to privacy and copyright laws. For specific needs, pre-existing datasets are also available that can be purchased from providers or obtained by collaboration with specialized data vendors.
A. Ensuring data diversity and representativeness in the dataset
Including a diverse range of text samples across demographics and product categories is crucial for a comprehensive understanding of customer sentiment, allowing the model to accurately interpret expressions, slang, and colloquialisms from various groups and contexts.
B. Strategies for preparing raw text data
Careful selection and thorough preparation are crucial for effective text annotation in customer sentiment analysis. This involves ensuring the quality and relevance of the data for extracting accurate insights.
These strategies include:
Data Selection: The priority is to select texts that are representative of the entire dataset, ensuring that there are no biases that could affect the sentiment analysis results.
Data Cleaning: Removing irrelevant content, such as HTML tags or extraneous whitespace, to ensure clarity. This can be automated as well, using regular expressions and text processing libraries.
Tokenization: The text is broken into smaller units, called tokens. Tokens can be words, numbers, or punctuation marks. The purpose of tokenization is to simplify the subsequent processes in text analysis by dealing with smaller and more manageable pieces of text.
Normalization: Normalization is the process of converting tokens into a standard or canonical form. This may include converting all text to lower case, removing punctuation, correcting misspellings and converting slang to formal language.
Tokenization typically occurs before normalization in the text annotation process. This is because you need to break down the text into tokens (the smallest units that carry meaning) before you can start normalizing these tokens into a standard form.
For example, let’s consider a simple sentence from a customer review of a smartphone:
Original Sentence: “I’m loving the new smartphone! It’s AWESOME!!”
Tokenized Output:
[“I”, “‘m”, “loving”, “the”, “new”, “smartphone”, “!”, “It”, “‘s”, “AWESOME”, “!”, “!”]
The sentence has been broken down into words and punctuation marks, each being a separate token.Normalized Output:
[“i”, “am”, “love”, “the”, “new”, “smartphone”, “!”, “it”, “is”, “awesome”, “!”]
The normalization process has standardized the tokens by making them lowercase, reducing words to their base form, and removing redundant punctuationLanguage Identification: Ensuring that the dataset is uniform in language, especially for multilingual sources.
De-duplication: Eliminating repeated content that could skew analysis results.
Context Preservation: Maintaining sentence structure and meaning for accurate sentiment interpretation.
These steps create a solid foundation for the annotators, enabling them to focus on the nuances of customer sentiment.
2. Creation of Annotation Guidelines
Establishing well-defined annotation guidelines is critical to achieving consistent and reliable sentiment analysis outcomes. These directives serve as a benchmark for annotators, ensuring that the sentiment of customer feedback is interpreted accurately and uniformly.
A. Importance of having clear and consistent annotation guidelines
Clear guidelines are essential as they:
- Standardize the annotation process, reducing subjective differences among annotators.
- Improve the quality of training data for machine learning model development.
- Ensure reproducible results, crucial for validating and refining sentiment analysis algorithms.
- Facilitate efficient training of new annotators, streamlining workflow.
- Minimize errors and inconsistencies, enhancing the robustness of customer sentiment analysis.
This ensures that sentiment analysis accurately reflects customer opinions, aiding businesses in making informed decisions.
B. Considerations for developing guidelines for quality text labeling
While developing annotation guidelines, it is essential to engage experienced annotators and subject matter experts to ensure that the criteria reflect the nuances of customer sentiment. These guidelines should be comprehensive yet flexible enough to cover various scenarios.
Here’s a table outlining key considerations:
| Consideration | Description |
|---|---|
| Clarity | Guidelines must be clear and unambiguous to prevent inconsistent interpretations. |
| Examples | Provide ample annotated examples to illustrate each sentiment category. |
| Iteration | Regularly review and update guidelines to capture evolving language use. |
The creation of annotation guidelines is a dynamic process, requiring input from diverse stakeholders to balance precision and adaptability.
3. Step-by-step guide to the text labelling process
It might be worth mentioning at this point that though the terms text annotation and text labeling are often used interchangeably, the two are not the same. There are several differences between text annotation and text labeling.
The text labeling process is a critical part of text annotation process, requiring careful organization and clarity.
It starts by identifying suitable labels and groups that accurately reflect the sentiments in customer feedback. To ensure the analysis’s integrity, these labels must be specific, exclusive, and arranged in a clear hierarchy with well-defined meanings.
Step 1: Identifying relevant labels & label groups for annotation
Selecting appropriate labels and label groups is the first critical step in the annotation process for customer sentiment analysis. To ensure clarity and precision in the data, one should consider:
- Positive, negative, and neutral sentiment labels
- Specific emotion tags (e.g., joy, anger, surprise)
- Intensity modifiers (e.g., mild, moderate, strong)
- Topic categories (e.g., service, product quality)
- Feature-specific tags (e.g., price, usability)
Step 2: Ensuring that Labels are Specific, Relevant, and Comprehensive
After establishing a range of labels, the next is to ensure each label is specific, relevant, and comprehensive, thereby facilitating a more accurate sentiment analysis.
| Criteria | Description |
|---|---|
| Specificity | Labels must clearly define the sentiment expressed. |
| Relevance | Labels should be pertinent to the domain of interest. |
| Comprehensiveness | Labels must encompass the full scope of sentiments. |
| Clarity | Labels need to be easily understood by annotators. |
Step 3: Ensuring Labels are Mutually Exclusive
In customer sentiment analysis, it’s essential to clearly categorize each text into a single sentiment label – positive, negative, or neutral – to eliminate confusion and overlap. This requires annotators to strictly adhere to specific criteria for each category.
For example, expressions of satisfaction like “happy” or “excellent” indicate a positive sentiment, whereas terms like “disappointed” or “terrible” suggest a negative one. To ensure accuracy, a secondary review by another annotator is recommended, along with using annotation tools that enforce these categorization rules.
Below is a simple guideline table for easy reference by annotators:
| Sentiment | Indicator Words | Exclusivity Rule |
|---|---|---|
| Positive | happy, satisfied, excellent | Each text can only be assigned one sentiment label |
| Negative | disappointed, poor, terrible | |
| Neutral | average, sufficient, fair |
Step 4: Organizing Labels Hierarchically
To enhance sentiment analysis, use a hierarchical label system with broad categories like Positive, Neutral, and Negative, further divided into specific emotions or attitudes. This method, supported by a specialized labeling tool, ensures precise categorization. For example, a review could be classified as Positive > Satisfied > Product Quality, clearly indicating satisfaction with the product.
Here’s a simplified version of this system:
| Main Category | Subcategory | Specific Sentiment |
|---|---|---|
| Positive | Satisfied | Product Quality |
| Customer Service | ||
| Excited | New Features | |
| Neutral | Indifferent | General Inquiry |
| Negative | Frustrated | Technical Issues |
This structured approach to labelling facilitates a more granular analysis of customer feedback, which can be invaluable for improving products, services, and overall customer experience.
Step 5: Creating Clear Label Definitions
To ensure precise and consistent dataset annotation, establish well-defined labels. These should categorize sentiments into broad categories (positive, negative, neutral) and specific emotions (frustration, satisfaction), including clear examples.
Conduct regular calibration sessions to align annotators’ interpretations of these labels, resolving ambiguities through group consensus. A final quality review by experienced reviewers is essential to maintain label consistency.
This labeling phase is just the first step in the text annotation process, leading to subsequent techniques that enhance the data’s quality and utility.
Unlock critical information in unstructured data to train NLP models
Human Powered Entity Extraction and recognition
4. Text annotation techniques used in sentiment analysis
 Example of sentiment analysis
Example of sentiment analysis
Sentiment analysis leverages diverse text annotation techniques to accurately interpret and classify emotions within text data.
Binary Sentiment Analysis
Binary sentiment analysis requires classifying text as positive or negative. This primarily deals with subjective statement identification, context-based polarity recognition, differentiating facts from opinions, ensuring consistency, and addressing ambiguities.
Multi-Class Sentiment Analysis
Multi-Class sentiment analysis classifies text into emotions like joy, anger, or sadness, requiring annotators to detect subtle language cues. Clear guidelines and inter-annotator agreement ensure consistent, accurate sentiment classification, enhancing algorithms’ comprehension of customer emotions.
Granular Sentiment Analysis
Granular sentiment analysis delves deeper by measuring the intensity of emotions or opinions in text, often using a scale like 1-5 stars in reviews for more precise sentiment rating. This detailed approach reveals subtle variations in customer opinions, invaluable for businesses aiming to closely assess customer satisfaction and make targeted improvements to their products or services.
These methods enable a finer understanding of customer sentiment, beyond simple positive, neutral, or negative classifications.
5. Dataset Management
Once the annotated dataset is prepared, next, dividing the data into training, validation, and testing sets can significantly impact the performance and generalizability of machine learning models.
An appropriate distribution is vital for an accurate evaluation of the sentiment analysis system’s predictive capabilities.
Strategies for splitting the annotated dataset into training, validation, and testing sets
How should one divide the annotated dataset into distinct training, validation, and testing sets to ensure the effectiveness of the sentiment analysis model?
The division of the annotated dataset is crucial for the model’s ability to learn, validate its learning, and then be tested for generalization.
Here are some strategies to consider:
- Random Splitting: Assign data points randomly to each set.
- Stratified Splitting: Ensure each set reflects the overall distribution of classes.
- Time-based Splitting: For time-sensitive data, split according to date ranges.
- Domain-specific Splitting: Separate data based on different domains or sources.
- Iterative Splitting: Use techniques like cross-validation for more robust model evaluation.
This segmentation enhances robustness and identifies model strengths and weaknesses. Effective dataset management is crucial for building a reliable sentiment analysis system that accurately interprets customer opinions for informed decision-making.
6. Testing, Refining, and Iterating
Initially, a small annotated dataset is used to train a preliminary model, which is then tested for performance. The model’s predictions are compared against a validation set to identify any misclassifications or biases.
Techniques such as confusion matrix analysis and precision-recall evaluation are employed to assess the model’s strengths and weaknesses.
Confusion Matrix
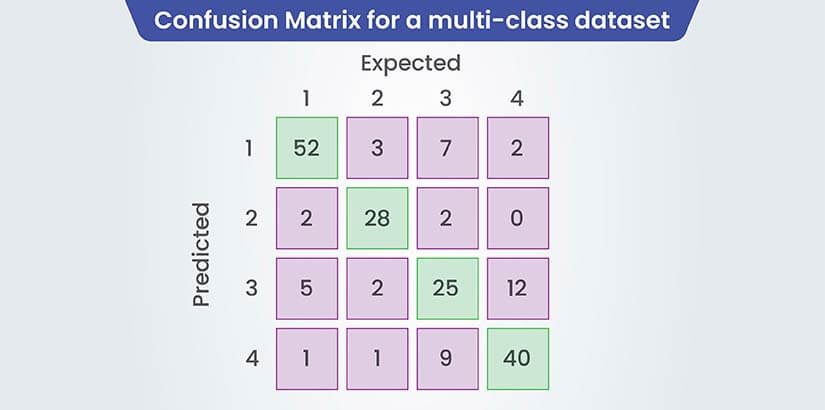 Confusion Matrix for a multi-class dataset
Confusion Matrix for a multi-class dataset
A confusion matrix is a table that is used to describe the performance of a classification model on a set of data for which the true values are known. It is particularly useful for binary classification problems but can be extended to multi-class classification as well. Here’s what it typically includes:
- True Positives (TP): The cases in which the model correctly predicted the positive class.
- True Negatives (TN): The cases in which the model correctly predicted the negative class.
- False Positives (FP): The cases in which the model incorrectly predicted the positive class (also known as Type I error).
- False Negatives (FN): The cases in which the model incorrectly predicted the negative class (also known as Type II error).
These values are used to calculate several metrics that provide insight into the quality of the classification:
- Accuracy: (TP + TN) / (TP + FP + FN + TN) – The overall correctness of the model.
- Sensitivity/Recall: TP / (TP + FN) – The proportion of actual positives that were correctly identified.
- Specificity: TN / (TN + FP) – The proportion of actual negatives that were correctly identified.
- Precision: TP / (TP + FP) – The proportion of positive identifications that were actually correct.
- F1 Score: 2 * (Precision * Recall) / (Precision + Recall) – The harmonic mean of precision and recall.
Based on these insights, the annotation guidelines are refined to address specific issues, such as ambiguous sentiment expressions or inconsistent labelling.
The iterative cycle involves re-annotating the text data with the updated guidelines and retraining the model to improve its predictive capabilities. This process is repeated until the model achieves a satisfactory level of accuracy.
To streamline this workflow, automation tools like active learning can be used, where the model suggests the most informative samples for human annotation, effectively reducing the workload and improving the model with fewer iterations.
Below is a simplified workflow table illustrating the iterative process:
| Step | Action | Outcome |
|---|---|---|
| 1 | Annotate initia dataset | Train preliminary model |
| 2 | Evaluat model performance | Identify errors and biases |
| 3 | Refine annotation guidelines | Improve data quality |
| 4 | Re-annotate & retrain | Enhanced model accuracy |
| 5 | Repeat steps 2-4 if necessary | Achieve satisfactory performance |
This cyclical approach ensures a robust sentiment analysis model that is well-tuned to the nuances of customer feedback.
Elevate the performance and capabilities of your AI and ML models.
Explore our text annotation and labelling services.
Quality Control in Text Annotation
Using iterative enhancement techniques can significantly improve the quality and reliability of the annotations that inform customer sentiment metrics.
Reviewing and refining annotations to address inconsistencies
The quality control phase following initial text annotation is crucial for ensuring accurate sentiment analysis. Key steps in this phase include:
- Consistency Checks: Verifying uniform application of annotation guidelines.
- Error Identification: Flagging and investigating potential mistakes.
- Inter-Annotator Agreement: Assessing agreement levels among annotators.
- Iterative Review: Conducting multiple review rounds for data refinement.
- Feedback Loop: Providing annotators with feedback to enhance future annotations.
Approaches to iterative improvement of the text annotation dataset
To enhance text annotation dataset quality, we use systematic approaches for quality control, including:
- Monitoring for consistency and accuracy against standards.
- Conducting inter-annotator reliability checks.
- Periodic retraining for guideline alignment.
- Employing machine learning for outlier detection and review.
These steps are key for maintaining high-quality annotations.
Training and Evaluation of Annotators – A Prerequisite
To ensure the reliability of data annotation in sentiment analysis, it is crucial to have a well-trained team of annotators.
Techniques for training annotators effectively
Ensuring high-quality text annotation for customer sentiment analysis requires effective training and evaluation of annotators. Key strategies include:
- Comprehensive Training: Providing detailed guidelines and real-case scenarios for a clear task understanding.
- Practical Sessions: Offering hands-on practice with feedback to enhance annotator skills.
- Regular Performance Reviews: Assessing annotators to identify improvement areas and offer specific training.
- Consistency Metrics: Using inter-annotator agreement measures for uniformity and objectivity.
- Support and Communication: Maintaining open channels for queries and fostering a collaborative learning environment.
These approaches collectively ensure reliable, accurately annotated data for sentiment analysis.
Methods for evaluating annotator performance and ensuring consistency
Evaluating annotator performance in sentiment analysis combines qualitative feedback on annotation nuances with quantitative, numerically measurable metrics to ensure consistent quality.
Here is a table summarizing key methods:
| Method | Description |
|---|---|
| Inter-Annotator Agreement (IAA) | Measures the level of agreement between annotators. |
| Annotator Accuracy | Compares annotations against a pre-defined gold standard. |
| Consistency Checks | Regular testing to ensure stable annotation quality over time. |
These methods help in identifying areas for improvement and ensure a reliable sentiment analysis process.
Points to consider while selecting text annotation tools
Sentiment analysis relies heavily on the quality of text annotation tools used. This section will explore the available tools and provide guidance to help you choose the most suitable platform for sentiment analysis tasks.
Establishing criteria based on accuracy, efficiency, and scalability is important for choosing a tool that meets project-specific needs.
Guidance on choosing the right text annotation tool for sentiment analysis
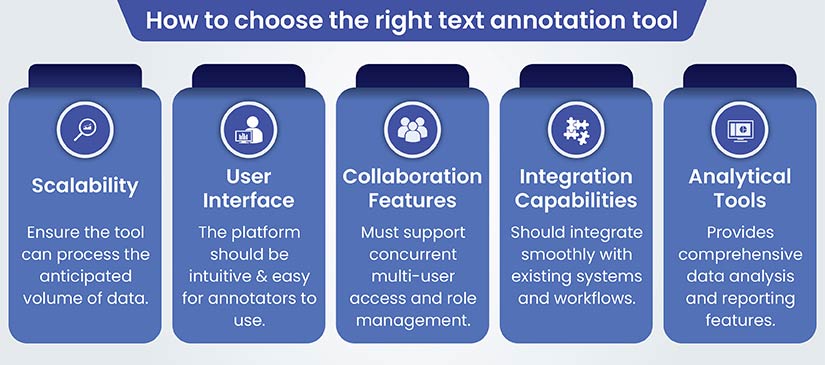
Examination of various text annotation tools and platforms
There are several tools and platforms available for text annotation. Here is a list of such tools along with their features:
- LightTag: Offers a platform for annotators and companies to label their text data in-house. It has different pricing packages, including a free starter package.
- Annotate: This is a document collaboration platform with features for document and PDF annotation, highlighting text, and color-coded and topic-based annotations.
- Innodata: A web-based text annotation platform designed for creating expertly labeled and annotated data at scale. It caters to complex documents and unstructured content.
- Kili Technology: Provides text annotation tools for a variety of text-based assets using intent classification, named entity recognition, and relation tasks.
- Labelbox: A data labeling platform that is versatile for annotating images, text, and video data. It supports various types of annotations and comes with built-in quality control tools.
These tools are designed to facilitate the annotation of text for different use cases, including machine learning training sets, document processing, and specialized fields such as medical data analysis. Each tool has its own set of features that cater to the needs of different annotation tasks.
AI-Driven Text Annotation Tools
AI tools streamline the text annotation process by automating the identification and categorization of emotions in text data. These tools use natural language processing (NLP) and machine learning to understand language nuances, enabling more precise sentiment analysis at scale.
You can read more about the machine learning trends using AI here.
Among the most popularly used AI tools, are the following:
-
Amazon Comprehend
This tool leverages machine learning to process natural language, extracting key insights from texts. It can identify sentiments, topics, categorize documents, and remove personal information, all without needing prior knowledge of machine learning.
-
IBM Watson Natural Language Understanding
This machine learning API analyzes unstructured text data, providing insights into sentiments, emotions, and syntax across languages. It allows for customizations and integrates with existing systems, supporting commercial use through IBM’s partner libraries.
-
Google Cloud Natural Language
Google’s machine learning powers this service, offering sentiment analysis and entity recognition. It includes syntax analysis and custom model training via AutoML, accessible through a REST API.
-
MonkeyLearn
This AI tool specializes in text analysis and data visualization. It offers both pre-built and customizable models for tasks such as sentiment analysis and topic classification, integrating with applications like Excel and Google Sheets. Its user-friendly interface facilitates easy creation of text analysis tools.
-
spaCy
A high-performance, open-source Python NLP library suitable for large-scale text processing. It includes Named Entity Recognition, POS tagging, and dependency parsing, supports multiple languages, and can be integrated with various machine learning frameworks for in-depth data analysis.
HitechDigital’s text annotation and labelling services successfully implemented an automated text classification and validation system for a German construction technology company, improving the performance of its AI model. This was achieved through handling large volumes of construction-related data, ensuring accuracy, and improving algorithmic performance, thereby benefiting the client’s data dissemination process. Read in detail about the case here.
Empower your NLP models with enhanced training data
Systematically identify, categorize and label textual data
Real world use cases
Text annotation has widespread applications across various industries:
- Trend Analysis: By annotating and analyzing customer sentiment over time, businesses can identify trends in customer opinion. This can be particularly useful for tracking the impact of new product releases, marketing campaigns, or changes in service.
- Customer Support and Feedback: Text annotation helps in categorizing customer support tickets based on sentiment, urgency, and topic. This can streamline support processes and ensure that critical issues are prioritized.
- Product Development and Improvement: By analyzing annotated customer feedback, companies can identify areas for product improvements or features that are particularly appreciated by users, guiding product development strategies.
- Market Research and Competitive Analysis: Sentiment analysis through text annotation can be used to compare customer sentiment towards different brands, products, or services, offering insights into competitive positioning in the market.
- Personalized Marketing and Sales Strategies: Understanding customer sentiment at an individual level can help in tailoring marketing and sales approaches, improving customer engagement and conversion rates.
- Social Media Monitoring: Text annotation is used to analyze sentiments on social media platforms, providing real-time insights into public opinion and emerging issues or crises.
- Voice of Customer (VoC) Programs: Sentiment analysis through text annotation is a key component of VoC programs, helping businesses to capture, analyze, and respond to customer feedback across various channels.
Conclusion
Text annotation for customer sentiment analysis is more than a mere technical undertaking. It’s an intricate balance of the subtle nuances of human language and emotion with the precision of technology. From the challenges of interpreting human idiomatic expressions to the choice of AI-driven tools, the field is not just about data processing. It’s about understanding the pulse of customer sentiment, capturing the essence of human expression, and converting it into actionable insights.
This process is as much technical as it is a strategic move that requires a deep understanding of both language and technology. The role of AI in text annotation, for instance, is not just about efficiency but about adding a layer of depth and insight to our understanding of customer sentiments.
As analyzing customer feedback is of primary importance, we are sure that the techniques and tools discussed in this article will be helpful in staying attuned to customers’ voices.
Identify human expressions to understand the pulse of customer sentiment.
Let us contribute to your text annotation efficiency.




