

- ML data can be collected through web scraping, APIs, sensors, enterprise extraction and synthetic generation.
- To prepare your collected ML data you will need to follow quality processes such as cleansing, enrichment, and validation.
- When you combine two or more types of machine learning data collection strategies (Hybrid), you can develop better AI models.
Table of Contents
- Defining AI data collection: Scope, objectives & challenges
- Key data collection methods for scalable AI models
- Post collection quality processes: Cleaning, enrichment & verification
- Which data collection method fits your AI use case?
- How HitechDigital supports data collection for ML projects
- Conclusion
The quality of your data collection for machine learning determines how well the AI models perform after they are developed. If there is any slippage during the process of data collection for AI models it can ultimately defeat your goals for developing AI.
According to studies, 74% of organizations face challenges scaling the value of AI despite 78% of organizations reporting adoption of AI. The most significant barrier is due to data complexity.
AutoML is projected to grow to over $61B by 2033 from its current level of over $3.5B in 2024. In order to support these growing systems, data pipelines need to be built to allow for continuous iteration.
Here we present a walkthrough on the machine learning data collection methods that distinguish successful high performing implementations from unsuccessful implementations that result in downstream failures.
Defining AI data collection: Scope, objectives & challenges
The process of AI data collection begins with clearly defining what data is needed, from which sources, and at what scale to help the intended machine learning use cases. Accuracy, representativeness, compliance, and long-term model performance should be the primary objective of the entire data collection activity.
Organizations struggling with issues of data silos, inconsistent formats, bias, privacy regulations, and high acquisition costs should consciously address these when collection data for their AI models. Addressing these challenges early on, ensures reliable datasets that truly enable effective, scalable AI-driven machine learning solutions.
According to industry reports, 64% of companies identify data quality as their number one obstacle and 77% report their data quality is either average or poor.
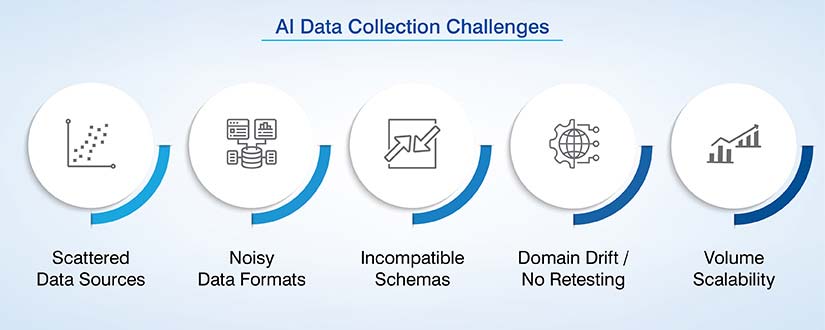
You should not consider data collection to be administrative overhead. View data sourcing for machine learning as an essential part of your overall AI/ML engineering infrastructure.
Key data collection methods for scalable AI models
You need to have an automated data collection strategy built into your AI driven systems to accommodate iterative tuning and continuous feedback loops.
Web scraping & automated crawling
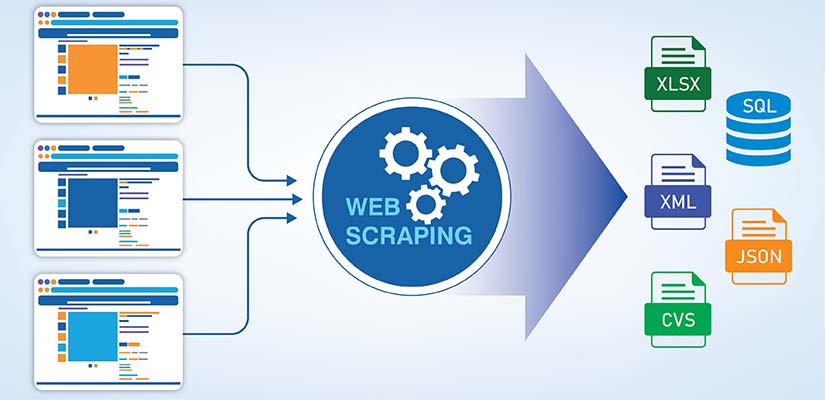
Web scraping is a method of programmatically extracting information from websites. Automated crawling systemically browses through web pages to find and collect relevant information in large volumes.
Setting it up
Set up your crawler to render JavaScript for dynamic content. Deduplicate early to avoid creating duplicate records in your dataset. Utilize tools like Selenium which can render dynamic content and provide pagination and rate limiting capabilities to crawl larger websites.
Besides providing metadata such as timestamps, source URL and category for filtering downstream, product catalogs may require a completely different parsing strategy than long form articles.
What to watch
Respect all robots.txt directives, copyright restrictions, regional privacy regulations (such as GDPR, CCPA, etc.). Collect only strictly necessary data points. Protect stored data by utilizing access controls and encryption. Design scrape for both real time vs batch data collection in ML to match model training cadence.
API-based data extraction
The primary advantage of using an API is that they provide structured data in a predefined format which eliminates the need to preprocess data prior to use. APIs are particularly suited for data sourcing for machine learning pipelines that process data from events or in real time.
Setting it up
Establish throttling, exponential back-off and request queuing for rate limiting data ingestion from one or many APIs. Create a method to ensure all incoming data from multiple API feeds adhere to a common schema. Standardize how fields are named, what type each field is and how values are formatted.
What to watch
Implement field level validation that can identify corrupted records upon ingestion rather than during model training. Create methods for implementing robust authentication handling, pagination logic and error recovery to ensure continuous operations.
Sensor, IoT & telemetry data collection
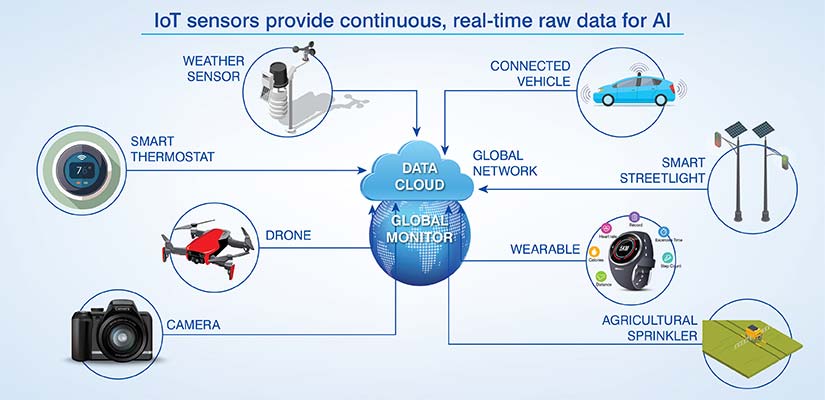
Industrial IoT is producing a large volume of real time, high frequency data to support predictive maintenance, smart manufacturing and supply chain logistics.
Setting it up
Determine the correct sampling rate for each type of sensor based on the ML models temporal resolution. Utilize closed loop, continuous feedback loops for operational adjustments as needed.
What to watch
Implement data validation integrity checks at the point of data collection to prevent corrupted readings from entering into your dataset. Implement signal pre-processing methods such as filtering out noise, addressing missing values and normalizing sensors as close to the source as possible.
Enterprise data extraction (documents, records, databases)
AI-assisted OCR provides high-quality, over 95% accurate results for printed text trained on a large number of documents that are relevant to your enterprise’s specific domain.
Manual data entry includes an estimated 4% error rate. Automated systems resolve the absence of data in public sources regarding domain specific information available within enterprise systems and inaccuracies caused by manually entering data.
Setting it up
Automated systems will be able to pull the necessary data from various organizational knowledge repositories. They will be able to pretrain LLMs using domain specific data sets and historical decision making processes and use those same archives to develop customer service AI.
What to watch
Schema normalization should be completed as soon as possible. Legacy systems contain duplicate information that was entered identically in different departments at different points in time and therefore have to be normalized prior to being used in automated systems.
Human-generated data collection (expert labeling)
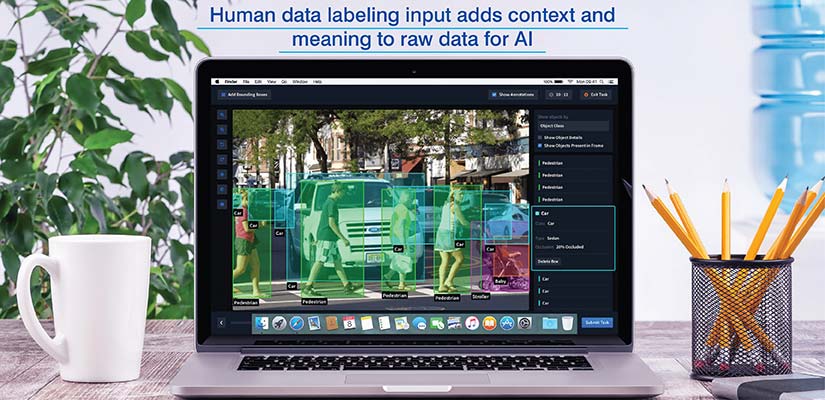
The data labelling market reached a high of $18.63 billion in 2024 and is predicted to cross $57 billion by 2030.
Outsourced providers handle 69% of labelling work. Crowdsourcing data for machine learning can either become an asset or liability based on how well outsourced providers are able to deliver in terms of the quality of implementation.
Setting it up
Systematically measure Inter-annotator agreement (IAA). For 2 annotator tasks use Cohen’s kappa. For multi annotator tasks use Fleiss’ kappa or Krippendorff’s Alpha. To filter participants, validate their accuracy against known examples.
What to watch
Use clear instructions, calibration of complexity and representative examples to improve annotation consistency. Preference data created through human input can influence the models behavior when you are fine tuning an LLM or running RLHF.
Synthetic data generation & data augmentation for machine learning
It is estimated that the global synthetic data market will grow from an approximate $432 million in 2024 to almost $8.9 billion by 2034.
In cases such as fraud detection or in areas of equipment failure or sensitive privacy, use synthetic data generation methods for AI. Synthetic data can be used to create additional instances of the underrepresented classes which will improve model performance on those classes.
Setting it up
Schema preserving transformations can be applied to extend the size of existing datasets like text paraphrasing, structured data perturbation and format variations. The transformations allow for scaling the volume of the training data.
Data augmentation for machine learning increases the volume of data available for testing and training AutoML experiments while preserving the original distribution of the dataset.
What to watch
Synthetic data can reveal details about the original database. Therefore, users should apply differential privacy techniques to enable analytics to be performed while avoiding violations of privacy laws.
Post data collection quality processes: Cleaning, enrichment & verification
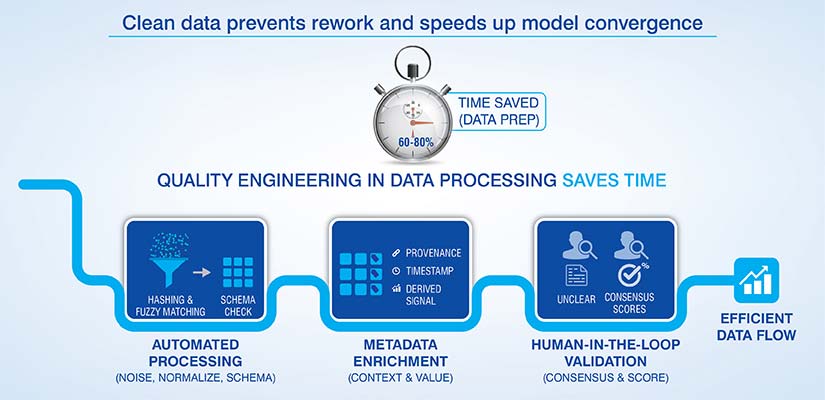
With data preparation accounting for up to 80% of data science effort, quality engineering becomes far more effective when supported by outsourced AI data preparation capabilities.
Following are some of the ways in which this can be done:
- Noise reduction, normalization and schema correction: Include these functions in your automated data processing pipelines. For example, use perceptual hashing and fuzzy matching for generated fields and text.
- Add value with metadata: Add information or context about your data through metadata tags. Tag how the data was provenanced, timestamped and what derived signal you used to enrich your data.
- Human in the loop validation: Validate your annotations by comparing them against other annotators and provide consensus scores for unclear cases.
Following are the quality metrics to track:
| Metric | Purpose | Application |
|---|---|---|
| Precision & recall | Classification accuracy | Any classification-oriented data |
| Completeness | Coverage assurance | All dataset types |
| Consistency | Logical coherence | Cross-source data integration |
| Bias indicators | Fairness assessment | Model outcome equity |
Which data collection method fits your AI use case?
Use the appropriate ML technique for a particular requirement instead of using what is most familiar to you.
- The supervised model has to have an annotated dataset that will require crowdsourced annotation or expert annotation. The unsupervised model can be applied to large amounts of un-annotated data which may also need to be extracted through scaled web scraping and/or API extraction.
- You should consider the volume of data required, as well as the types of data you are working with and the speed at which you want to operate i.e., batch vs. real time.
- Consider whether you need to track common events, or edge cases and design your pipeline based on your compliance needs.
- Hybrid methods that combine multiple different methods will generally outperform single method approaches.
How HitechDigital supports data collection for ML projects
HitechDigital supports the creation of ML-enabled datasets by supporting enterprise clients throughout the data preparation process:
- Data sourcing and aggregation: Collecting large volumes of text, document and structured data to match a client’s specific needs.
- Standardizing and enriching data: Reducing the amount of noise in the raw data as part of data processing and enrichment process.
- Data moderation and compliance: Filtering out unsafe content that may be toxic or contain personally identifiable information while adhering to applicable laws and regulations.
- Classification, segmentation and intent: Highly qualified annotators, by data annotation and labeling service providers, with relevant experience in the client’s industry for entity recognition (NER) solutions.
- Synthetic data and augmentation support: Synthesizing rare events and developing augmentation pipelines and simulation workflow.
- Validation and quality assurance (QA): Implementing multiple layers of QA processes, consensus scoring and error analytics to validate dataset accuracy.
HitechDigital’s capabilities are scalable, support global language, provide enterprise grade security and utilize a distributed workforce to meet the needs of its clients.
Aggregated, Validated & Cleansed Government Contact Database

An IT firm located in Florida was providing a government-spends online platform and was experiencing difficulties maintaining a current contact list of federal, state and local government agencies’ contacts that were drawn from multiple uncoordinated sources.
HitechDigital collected contact info from over 75,000 web sites for all U.S. government agencies at the federal, state and local levels. We used crawler software to validate and standardize nearly 500,000 contact records collected from these sources by validating each record through a manual review process.
The end result was:
- 99.5% accurate, reliable contact database
- Improved user experience on the platform
- Greater operational flexibility and reduced data maintenance effort
Conclusion
The quality of your machine learning results is directly tied to how good your training data is. All the above-mentioned methods have been developed to address various pipeline issues. There isn’t one single best strategy for obtaining quality data. The best strategies will be those that utilize a combination of methods and pair each method with a particular need.
Systematically developing and collecting training data sets is a basic approach companies investing in AI need to follow. Those that ignore cultivating systematic training data collection processes are bound to experience data quality issues preventing ML initiatives from achieving their full potential.
Turn data collection into analytics-ready datasets
Reduce manual effort with scalable, quality-driven data collection processes

