

- Synthetic data for computer vision helps fill a practical gap: real-world vision data is often hard to collect, sensitive to use, and inconsistent in quality, which slows training and leaves rare events underrepresented.
- Teams use 3D simulation and procedural generation to produce diverse scenes with clean, reliable labels at scale, without waiting months for the right conditions to happen in the real world.
- When you blend synthetic datasets for deep learning with real field images, models tend to generalize better and stay steadier on edge cases that would otherwise be missing or too expensive to capture.
Table of Contents
- What is Synthetic Data for Computer Vision?
- Why Use Synthetic Data Generation for Training Computer Vision Models
- Types of Synthetic Data for Computer Vision
- Step-by-Step Guide: How to leverage Synthetic Data Generation to Train Models
- Challenges and Limitations in Implementing Synthetic Datasets for Deep Learning
- Future Outlook: The Role of Synthetic Data Generation in Scalable AI
- Conclusion: Making Synthetic Data Work for You
Real-world data is tough to process. It’s hard to gather, slow to label and train computer vision models while being expensive to manage. And it’s often biased, reflecting only certain places, times or demographics. On top of that, privacy rules limit what you can even store and share.
Think about those rare moments that break a model, like a sudden glare at night or a damaged barcode. They just don’t appear often enough in real data to train on effectively. This is where synthetic data completely changes the game.
You can create scenes at any scale you need, play with lighting and weather conditions, and intentionally insert those tough edge cases. The labels get generated automatically, which makes sure everything is consistent and precise. Now, synthetic data doesn’t replace real field data. It’s meant to fill the gaps and speed up iteration cycles. And that’s important across a lot of different domains.
- A driving stack can practice heavy rain, fog and near misses in a completely safe loop.
- A retail system can learn from countless shelf layouts, occlusions and new packaging designs before a single store gets updated.
- And medical teams can model rare conditions without ever compromising patient privacy.
So, in this article, let’s look at what synthetic datasets for deep learning actually are, how expert teams generate them, and where they fit into a training pipeline. The article shares how to blend the synthetic datasets with real data, point out common mistakes to avoid, and talks about validating results. It also shares how you should build this in-house versus bringing in a partner.
What is synthetic data for computer vision?
Synthetic data generation for computer vision refers to artificially-generated visual data, such as images and videos, that mimics real-world scenes to train AI models. It is created using techniques like 3D modeling, computer simulations, and generative AI models like GANs.
Synthetic data is used to overcome the limitations of real-world data, such as scarcity, high cost, privacy concerns, and the difficulty of capturing rare events, providing a scalable and flexible alternative for training more robust and accurate models
Why use synthetic data generation for training computer vision models
So, you’ve got the basics of what synthetic data is and how it’s made. What’s next? How it helps in your day-to-day work. The short answer: it helps computer vision models to learn faster, break less often in production and stay fair across different people and places.
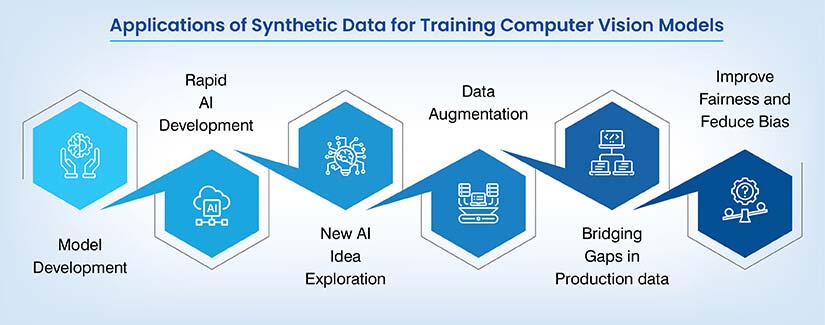
Developing robust, generalizable models
Real scenes are always changing. Lighting, angles, backgrounds and those rare events can easily throw a model off. Synthetic data lets us vary these factors on purpose, so the model actually learns how to handle them. The result? Better performance on new sites, new cameras and in new regions.
Rapid AI development
Collecting and labeling data real footage takes weeks. But with a generator in place, you can create new images in hours, retrain and test quickly. Teams use this loop to ship improvements faster and react to new edge cases without having to wait for field data.
Exploring new AI ideas
How many early experiments stall because there’s no dataset yet? Synthetic scenes give you a safe sandbox to try out new architectures, loss functions and prompts. If an idea looks promising, a small, targeted real-world collection of AI training data can then confirm it.
Data augmentation that goes further
Standard augmentation just edits what you already have. Synthetic data creates completely fresh scenes with new objects, poses and layouts. When used together, these methods expand the diversity in your computer vision training data and help reduce overfitting.
Bridging gaps in production data
Some events are just too rare or unsafe to capture think near crashes or equipment failures. Others are blocked by privacy or access limits. This is where you need to fill those holes using AI model training with synthetic data so the model sees what it needs to handle before it ever goes live.
Improving fairness and reducing bias
If your dataset is skewed toward certain locations or demographics, your model will be too. With synthetic data for computer vision, balance skin tones, body types, ages, clothing and environments. Script even coverage of lighting and weather, so accuracy doesn’t drop for any group or region.
When used well, synthetic datasets for deep learning are an incredibly practical tool. They help us build stronger models without having to wait on luck or perfect field conditions.
Annotation workflows and synthetic data pipelines can fast-track your AI model development
Need scalable, high-quality computer vision training data?
Types of synthetic data for computer vision
Synthetic data for computer vision includes various forms of visual data like RGB images, segmentation maps, depth images, LiDAR, and infrared images. These types can be categorized by their creation method, such as fully synthetic data (3D rendered), GAN-generated images, and augmented real data, or by their composition, such as fully synthetic, partially synthetic, and hybrid datasets.
Types of synthetic datasets for deep learning
- Fully synthetic: The entire dataset comes from simulators or 3D engines. This is really useful for rare or unsafe scenarios and helps with fast iteration.
- Hybrid datasets: This is a mix of real and synthetic images. It’s what you see most often in production because the real data grounds the model, while synthetic data expands its coverage.
Core elements
- 3D rendering: Use engines to create photoreal scenes where you can control the lighting, textures and camera optics.
- Physics engines: These make sure objects move and interact realistically in terms of collisions, gravity, fluids and cloth.
- Procedural generation: Use scripts to randomize assets, poses, weather, defects and backgrounds. This really boosts diversity and reduces overfitting.
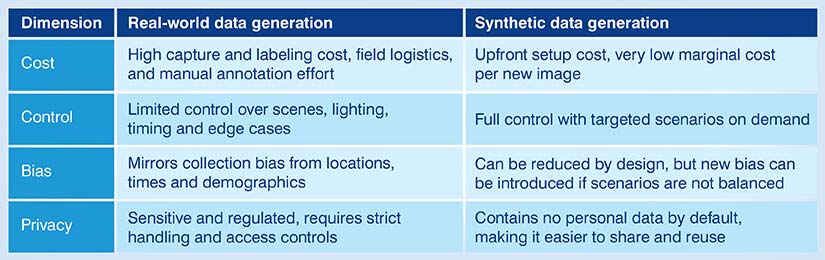
Real-world data generation vs. Synthetic data generation
| Dimension | Real-world data generation | Synthetic data generation |
|---|---|---|
| Cost | High capture and labeling cost, field logistics, and manual annotation effort | Upfront setup cost, very low marginal cost per new image |
| Control | Limited control over scenes, lighting, timing and edge cases | Full control with targeted scenarios on demand |
| Bias | Mirrors collection bias from locations, times and demographics | Can be reduced by design, but new bias can be introduced if scenarios are not balanced |
| Privacy | Sensitive and regulated, requires strict handling and access controls | Contains no personal data by default, making it easier to share and reuse |
Step-by-step guide: How to leverage synthetic data generation to train models
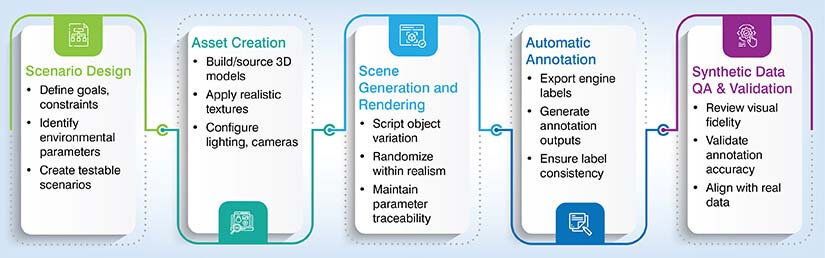
A good workflow ensures that synthetic data remains useful and accurate. Here’s a simple path teams use in practice for synthetic data generation.
The 5-Step Synthetic Data Generation Workflow
Scenario design
- Start with the goal. Define the tasks, edge cases and constraints first.
- Then list the environmental parameters you care about like time of day, weather, sensor specs, motion blur and occlusion.
- Write these up as testable scenarios so one can check later that they actually covered them.
Asset creation
- Next, build or source the 3D models of objects, people and environments you need.
- Add textures and materials that match the real world.
- Set up lighting rigs and camera parameters to mimic production sensors. For computer vision training data, small choices like focal length and noise profiles are what help reduce the gap to reality.
Scene generation and rendering
- Use scripts to place objects, vary poses and control things like occlusion, backgrounds and clutter.
- It’s important to randomize lighting, materials and camera viewpoints, but only within realistic ranges. Render multiple passes as needed.
- And for synthetic data generation at scale, keep a clear naming scheme so every image links back to the parameters that produce it.
Automatic annotation
- This is where labels are exported straight from the engine.
- Common outputs include bounding boxes, instance and semantic masks, depth maps, keypoints, surface normals and optical flow.
- Because the labels come directly from the simulator, they’re super consistent and precise, which is a huge help for synthetic datasets for deep learning.
Synthetic data QA and validation
- Check visual fidelity with spot reviews and basic metrics like sharpness and exposure.
- To validate label accuracy, sample images and compare the annotations to what a human would draw.
- Align distributions by comparing object counts, sizes and lighting to real data.
The final step is to close the loop: train a small model and measure mAP and recall on a real validation set. If that gap is too big, go back and adjust assets, lighting or randomization and try again.
Tip
Automate as much as you can. A repeatable pipeline makes AI model training with synthetic data faster and easier to debug.
Build, validate, and manage production-ready computer vision training datasets
Looking to operationalize synthetic data generation at scale?
Challenges and limitations in implementing synthetic datasets for deep learning
The benefits of implementing synthetic data are covered above. Now for the hard parts. Synthetic data is powerful, but teams often hit limits when they try to move from a demo to full production.
Data quality limitations
If a render just looks wrong, the model can learn the wrong cues. Low-quality textures, odd lighting, or unrealistic motion create a domain gap that hinders real-world accuracy. The small details really matter, like sensor noise, lens distortion and motion blur. You also need a ton of variety. Reusing the same assets and camera angles will cause overfitting to synthetic patterns, which is a big problem.
Privacy concerns
Synthetic data usually avoids personal information, but privacy isn’t automatic. If you start basing assets on real people or rebuilding scenes from sensitive footage, you could bring risk right back into the picture. Document how assets are created, avoid 1 to 1 replica of individuals, and review all outputs for any chance of re-identification.
Technical and practical challenges
Building a reliable generator takes time, tools and skill. You need artists for the assets, engineers for the pipelines, and ML folks who can tune domain randomization and measure the results. Rendering at scale can get expensive without a solid compute plan. And integration is another hurdle. The synthetic data must fit your labeling formats, training code and MLOps stack, otherwise it will just slow the team down instead of helping.
Lack of standardized tools and methodologies
There’s no single playbook for this yet.
Engines, file types and labeling conventions are different across vendors and teams. This makes benchmarking a pain and complicates collaboration. You might spend a lot of effort just converting formats or matching coordinate systems. What helps? Clear internal standards. It also helps to have a small set of shared metrics, like mAP on real validation sets, failure case coverage and synthetic to real performance gaps.
When used with care, synthetic data is a strong addition to any computer vision training. Treat these limits as design inputs, not afterthoughts.
Future outlook: The role of synthetic data generation in scalable AI
The direction is clear. Synthetic data is moving from nice to have to standard issue.
Integration with simulation-based reinforcement learning
The most interesting shift we’re seeing is the link to simulation-based reinforcement learning. Think about it: the same worlds used to train agents to act can supply labeled frames to teach models to see. Perception and policy no longer have to live in separate silos.
Feeding foundation models for vision
Foundation models for vision are also changing the picture. They need incredible breadth and balance. Carefully curated synthetic datasets can cover the long tail and safety scenarios that public datasets just miss. If one can align them with real distributions and validate them on fixed test sets, pretraining on synthetic data can shorten fine-tuning time and lower costs.
Trends to watch
The medium-term trends all point in the same direction.
Finally, operations are catching up. Teams are building dashboards that track coverage, label accuracy and synthetic to real performance gaps over time. That level of visibility is what turns synthetic data for computer vision into a reliable pillar of scalable AI.
Conclusion: Making synthetic data work for you
Synthetic data gives you speed, control, diversity and scale. Create scenes on demand, tune lighting and sensors, and cover the edge cases that real data collections always miss. The labels arrive with each render, which keeps computer vision training data consistent. When we use it alongside real images, these synthetic datasets for deep learning help models generalize better and hold up in production.
The path forward is pretty simple. Start small with one clear problem and a short list of scenarios. Validate every single step with a real, fixed test set. Let the training feedback guide what you generate next. When you start seeing gains on real data, that’s when you scale the pipeline, but with care. Keep your assets organized, automate QA, and measure the synthetic-to-real performance on every single release.
If you take this steady approach, AI model training with synthetic data will become a reliable part of your workflow. You’ll ship faster. You’ll reduce risk. And your model will finally see the world it’s going to face, not just the world you happened to capture.
Fix errors and gaps in large real estate data repositories
Prepare clean datasets ready for analytics and modeling

