

- Video annotation transforms raw footage into structured training data by labeling objects, actions, and motion across frames for contextual model learning.
- Human-in-the-loop QA and precise annotation tools reduce noise, minimize rework, and enhance model accuracy and real-world reliability.
- Growing real-time, context-aware AI systems demand precise video annotation for building smarter, scalable, and safer machine learning solutions..
Table of Contents
- The importance of video annotation in machine learning
- What is the purpose of video annotation in machine learning
- How video annotation enhances machine learning performance
- What does the video annotation process involve
- Temporal consistency & object tracking across frames
- Tools and techniques that help
- Challenges in video annotation for ML
- Human-in-the-Loop for video annotation accuracy
- Business and operational impact of high-quality video annotation
- Why choose specialized video annotation services
- Conclusion
The importance of video annotation in machine learning
Video annotation is all about labeling moving objects and actions across frames so models can learn from motion and context. We use a video annotation tool to mark boxes, polygons, keypoints and actions, frame by frame. This video annotation process is part of our video data preparation. It’s what turns raw footage into video training datasets for real AI projects.
What is the purpose of video annotation in machine learning
The main purpose is to create clear training signals. This helps models detect, track and reason about change over time. Good labels improve recognition, tracking and short term forecasting. They also set the foundation for sound video annotation techniques and best practices during a project.
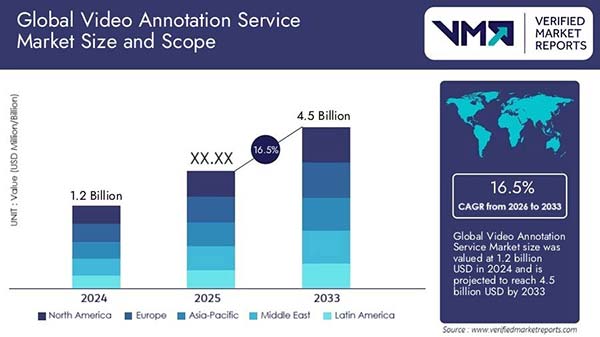
The growth we’re seeing in video annotation is really promising. The Video Annotation Service Market size was valued at USD 1.2 Billion in 2024 and it’s all set to reach USD 4.5 Billion by 2033. Source
Video annotation has already proven its worth in extracting valuable insights and supporting tasks like object detection, behavior analysis and semantic understanding across different industries. Here’s how various industries use video annotation and labeling for their AI and ML projects: Source
How is video annotation different from image annotation?
Image annotation deals with a single frame. Video adds the element of temporal continuity. You have to keep object IDs consistent across frames, manage occlusion and re-appearance and record scene dynamics like speed, trajectory and interactions. This continuity helps with object tracking, interpolation between frames and temporal segmentation—things that image tasks just don’t require.
Where is video annotation relevant today?
- Autonomous vehicles: to track pedestrians, cyclists, lanes and signs for safer planning.
- Surveillance: to follow people and vehicles across cameras and flag risky activity.
- Sports analytics: to track players and the ball to study movement and tactics.
- Robotics: to map space, avoid obstacles and learn pick and place actions.
These use cases rely on high quality labels that feed accurate models and scalable video training datasets.
How video annotation enhances machine learning performance
Video looks simple until you try to teach a model to read it. Motion and context shift from frame to frame, and video annotation is what ties those frames into a single story. With clear labels, models learn patterns across space and time, keep the same ID as objects move and recover after a brief occlusion. Strong labels lead to steadier tracking, cleaner predictions and better decisions.
Labeled video teaches spatiotemporal patterns
Models learn from examples, not from guesses. With video, the signal is both space and time. An accurate annotation method marks what shows up in each frame and how it changes. That gives models motion cues, scene context and cause-and-effect hints you’d never get from just a single image. The result? Better detection, stronger object tracking and more stable predictions when scenes shift. Our teams turn raw clips into training sets by labeling identities, boundaries and events across sequences. This is really the foundation for modern tracking and action recognition.
Context holds the thread: continuity, tracking, occlusion
Real footage gets messy. People cross paths, vehicles block each other and objects leave the frame only to return later. Temporal continuity is what keeps the same ID across frames and helps recover after short gaps. Public benchmarks show how consistent IDs and association rules can turn per-frame boxes into tracks you can trust. This process teaches models to follow entities over time, predict short term motion and stay steady when visibility drops. It’s the difference between a box that flickers and a track that tells a complete story.

Where it shows up: cars, sports, and surveillance
Self-driving stacks learn to spot and track pedestrians, cyclists, lanes and signs as scenes change. A lot of datasets pair camera views with depth or LiDAR and include IDs for evaluation. In sports analytics, tracking players and the ball across possessions helps create clean event logs and movement statistics. For surveillance, action datasets help models learn common activities, which improves search and incident review when the context shifts frame by frame. Clear labels are what make these results possible at scale.
Scale annotation without compromising on video quality.
Build stronger annotated video datasets.
What does the video annotation process involve
The video annotation process includes several methods, and no single method fits every scene. You have to choose what matches the object’s shape, how it moves and the decision your model needs to make. Making the right choice speeds up the video annotation process and builds stronger annotated video datasets.
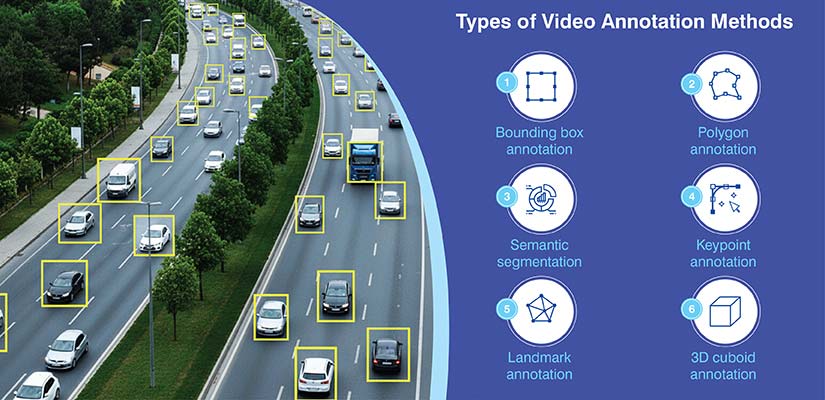
Bounding box annotation
Boxes mark where an object is, and they do it fast. They scale easily across long clips and crowded scenes. We use them for vehicle detection and people tracking in surveillance feeds when coverage is more important than perfect shape. The trade-off, of course, is accuracy around the edges because boxes can pull in background noise and overlap. We set keyframes and use interpolation to keep the tracks steady. For projects involving video surveillance anomaly detection, these techniques help maintain tracking accuracy and identify irregular movements more effectively.
Find out how a leading video annotation service provider from India, annotated and categorized volumes of vehicle and pedestrian image datasets from US and Canada traffic feeds, creating high-quality training data to improve machine learning model performance.
Polygon annotation
Polygons trace the real outline of an object. We pick this when shape is what drives the decision, like for road sign detection or complex machinery. You get pixel level precision and cleaner masks for training. But it costs more time per frame, so you have to plan your video data preparation with a mix: polygons for crucial classes and boxes for everything else.
Developed a three-step workflow delivering 1,000 annotated damage assessment frames daily to municipal agencies, using bounding boxes, polygons, and Roboflow for precise object annotation.
Semantic segmentation
Segmentation labels every single pixel. It’s about scene understanding, not just spotting objects. For example, urban navigation systems learn drivable roads, sidewalks, lane markings and static objects with total clarity. In medical video, it separates tissue types and tools. You use it when the full context really matters. Just expect a higher effort and stricter QA process.
Keypoint annotation
Keypoints tag joints, facial landmarks or other articulation points. You’d use this for pose estimation, gesture recognition and motion analysis. Sports teams track limb angles with it. Safety systems use it to flag risky postures. We choose keypoints when the relative geometry is more important than the overall shape.
Landmark annotation
Landmarks focus on faces and biometric regions. Use them for driver attention monitoring, fatigue cues and coarse emotion signals. They support gaze zones and blink rate tracking. Just be sure to watch for bias and lighting changes during collection and review.
3D cuboid annotation
Cuboids add depth to the equation. They capture orientation and size in 3 dimensions, which helps with collision risk, path planning and shelf or bin alignment in warehouses. We use cuboids for autonomous robots and indoor vehicles where distance and yaw are critical. Multi-view cameras or depth sensors can raise the label quality and reduce guesswork.
You have to choose with intent. And combine methods when needed. That’s how computer vision video annotation converts raw clips into useful video training datasets for real AI projects.
Annotated videos to create a dashboard of directional traffic volumes

A California-based data analytics firm needed to convert pre-recorded and live traffic video into directional vehicle counts and classifications (by turn, direction, type) to feed ML models.
HitechDigital annotated hundreds of thousands of video frames via a five-step workflow: labeling, segmentation, auditing, multilayered quality check and delivered structured, high-quality training data to the client.
The final deliverables led to:
- 250,000+ video frames accurately annotated with object labels
- 98% annotation accuracy achieved through multi-level QA checks
- 100% delivery compliance across all project timelines
Temporal consistency & object tracking across frames
Labeling every single frame is expensive. Most of our teams tag keyframes and then use temporal interpolation to fill in the rest. The tool predicts how boxes, polygons and keypoints move between the anchors. If you have smooth motion, you need fewer anchors. Fast scene changes need more, plus quick fixes for any drift.
Tracking consistency is what holds the story together. Each object needs a stable ID as it moves, leaves and returns. Occlusion and motion blur make this tough. Good labels carry the same ID, mark visibility and note when an object is fully hidden. These habits produce cleaner video training datasets and teach real spatiotemporal patterns, not just frame-by-frame guesses.
Tools and techniques that help
Some tools and techniques help manage the video annotation process better than ever. Here are a few of them:
Interpolation algorithms
From a few keyframes, the tool estimates the in-between positions. Linear or spline paths work well for steady motion. Tracker assisted interpolation helps when the speed changes. We just add more keyframes at turns, merges or scene cuts. This is a core video annotation best practice for long clips.
Optical flow
Optical flow maps pixel motion between frames. It nudges boxes, polygons and keypoints along the true path, even with some mild blur. It also helps with short occlusions and small, fast objects. It’s smart to pair flow with ID rules to reduce swaps.
Manual verification
Humans have to close the loop. We review hot spots: occlusions, overlaps, entries and exits. You sample at intervals, compare tracks side by side and fix ID swaps early. A light human in the loop pass converts auto labels into reliable annotated video datasets that are ready for computer vision video annotation projects.
Cut false positives and build models with confidence.
Transform raw videos into AI-ready data
Challenges in video annotation for ML
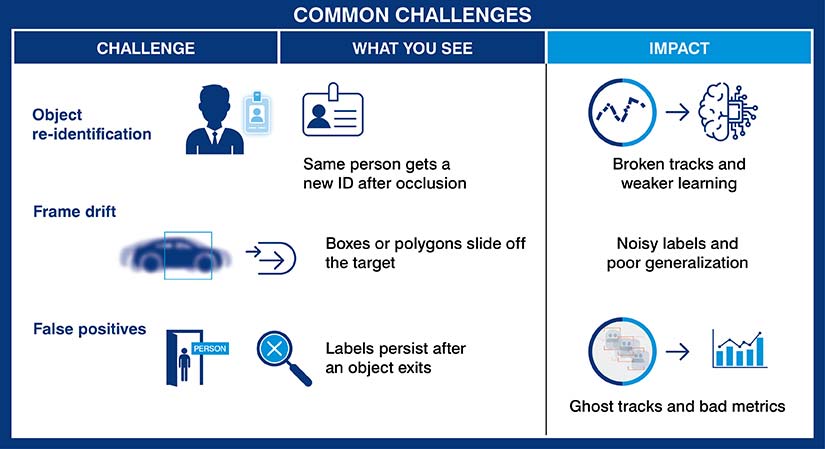
Video makes models smarter, but it also makes labeling harder. Bigger files. More motion. And way more ways to get it wrong. Here’s what usually trips up teams and how you can plan around it.
Scalability
One minute of video at 30 fps is 1,800 frames. Now imagine hours of it. Storage grows, label time grows and review time grows again. You have to plan the video annotation process for short clips, batching, keyframes and smart interpolation. We only label what supports the task and archive what we won’t use. Without that discipline, costs creep up and schedules slip.
Complexity
Annotators have to read the scene, not just draw shapes on it. A car slides behind a truck and appears 3 seconds later. Same ID. Crowds of people have tangled paths. Occlusions hide objects at the worst possible moment. We train on these tricky examples and write clear rules for entries, exits, occlusion flags and partial visibility. Small habits here can save you hours later on.
Quality control
Errors travel through time. A drifting box for 100 frames can poison an entire segment. A wrong ID at frame 50 breaks the track all the way to the end. That’s why we bake QA into our video training datasets pipeline. We spot-check merges, turns, handoffs and cuts. We compare tracks side by side. If the same mistake repeats, you fix the guideline, not just the frame. Treat QA like production work.
Tool limitations
Even great tools have their rough spots. Long clips can lag. ID helpers might confuse near-duplicates. Switching shapes or classes slows people down. Use presets, hotkeys and class lists that are tuned to your domain. Let the ID assist feature help, but switch to manual when it gets in the way. It also helps to trim clip length and preload only what you need to keep the workstation running smoothly.
None of this needs magic. It just takes clear rules, steady QA and the right tooling to turn messy footage into reliable annotated video datasets that models can learn from.
Human-in-the-Loop for video annotation accuracy
Auto-annotation definitely speeds things up. But humans keep it true. We let a model pre-label clips, then run a focused review to fix IDs, occlusions and missed events. This mix shortens the video annotation process and cuts down on rework for long sequences.
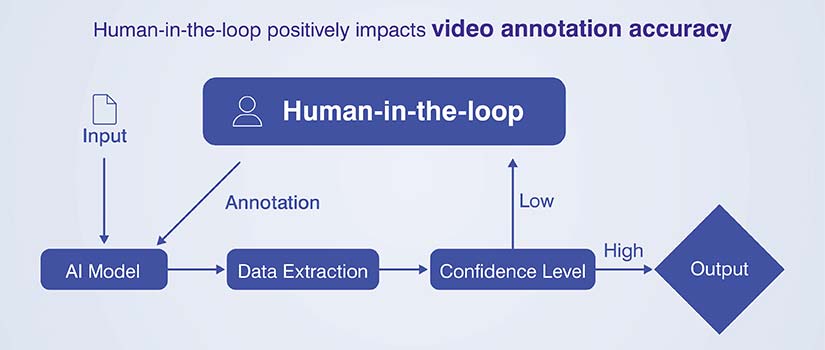
Expert reviewers are so important. They know the ontology, class rules and domain quirks. A sports clip doesn’t have the same cues as a warehouse video, right? We give them a short playbook for entries, exits, partial visibility and crowd scenes. We also equip the team with hotkeys, presets and a Video Annotation Tool that jumps to risky spots like turns and scene cuts.
You have to close the loop. Every correction is a training signal. We feed those fixes back into the assist model on a schedule, starting with high error classes or heavy blur. Then we retrain, test on a holdout set and only move forward when precision and recall go up. Over time, the model misses less and editors can do lighter passes.
Track the gains. Measure edit time per minute, ID swaps per track and drift per 100 frames. Use those numbers to tune your data prep and QA. The result is simple: cleaner labels and stronger training data.
Business and operational impact of high-quality video annotation
Good labels really show their value in production. Models trained on high fidelity annotated video datasets keep their head in tough scenes. Rain on the lens, night streets, partial views, crowded junctions. Clean tracks and clear class rules lower confusion, so predictions stay steady when it matters most.
Speed improves too. When the video training datasets are solid, there’s less rework and fewer hotfixes. Engineers get to spend their time modeling, testing and shipping. Not cleaning labels. That trims time-to-deploy and reduces those last minute surprises.
You can see it in the numbers:
- Faster model convergence. Target accuracy shows up in fewer epochs, so experiments move quicker.
- Lower false positives at inference. Tighter boxes, consistent IDs and accurate masks cut spurious alerts and retries.
- Safer autonomous operations. Strong tracking under occlusion and motion blur helps planning and control in the field.
Day to day, support tickets drop. Alert triage gets lighter. On-call stress goes down. You can scale data pipelines with confidence because the labels hold up under new footage. In short, strong video annotation improves accuracy, speeds delivery and keeps operations calm.
Why choose specialized video annotation services
Complex video needs more than just basic labeling. Specialized teams bring domain skill, custom tooling and strict QA to the video annotation process. They know the edge cases and set clear rules for entries, exits, occlusion and reappearance. That kind of discipline yields cleaner annotated video datasets and smoother video data preparation.
Outsourcing really helps when scale and speed matter. Providers can ramp up quickly, shorten turnaround times and run multi-stage reviews without slowing down your roadmap. You get consistent output across long clips and crowded scenes, which boosts downstream training on video training datasets. Partnering with AI video annotation experts ensures accuracy, scalability, and consistent quality for complex video projects.
Strong providers add real value:
- Frame sampling strategies that focus effort where motion or risk is highest.
- Auto-annotation pipelines with human QA to fix IDs, drift and blur.
- Dataset audits and feedback cycles that refine video annotation best practices and tighten your tool setup.
The result is steady data quality for computer vision video annotation and faster iterations on real projects.
Conclusion
Video annotation converts raw footage into training data a model can trust. It adds the missing link of time, keeps IDs consistent and captures context in busy scenes. With the right mix of methods, a clear process and steady QA, teams ship models that actually work in the real world.
The gains are practical. You get fewer false positives. Faster convergence. And safer behavior in the field. Strong annotated video datasets also cut down on rework and shorten release cycles.
As machine learning moves toward real time, context aware systems, the demand for precise, structured video annotation is only going to grow. If you invest in the strategy now, you’re setting yourself up for smarter, safer and more scalable AI tomorrow.
Turn raw video into reliable training data, fast.
Scale your video annotation workflow



