




Founded in 2007, the USA based medical knowledge management company manages a huge repository of healthcare data and shares relevant insights to consumers, patients, healthcare service providers and caregivers. These healthcare insights help make evidence-based healthcare decisions; right from healthy living and prevention to diagnosis, treatment and home care.
In order to further its healthcare data management business, the company was creating a comprehensive repository of healthcare data to be gathered from threads of more than 70 Redditt subgroups. The subreddits covered a wide spectrum of conditions from generic blood pressure, diabetes, diet and weight loss to serious ones like depression, cancer, liver, alcoholism and many more. The various types of data that was to be extracted included:
The company approached HitechDigital for capture and standardization of Reddit posts and discussions and classification according to race, ethnicity, age, etc.
The team at HitechDigital studied the processes to understand the scope of work, technology to be used, and the workflow to be designed. Following project requirements increased the challenges of the process:
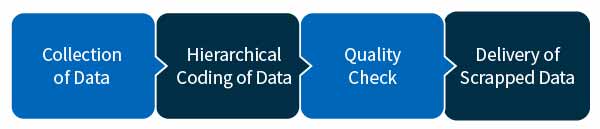
Designed an ongoing process of web scraping and unstructured data extraction using NLP and RPA to collect data from healthcare posts and discussion on Reddit subgroups. The automated data management workflow ensured that collected data upon reaching the final lag, would trigger a macro to move the data through a predefined quality and profiling process.
Manual data extraction requires complex workflows and significant hand-coding to extract, cleanse, and validate unstructured data. So, data professionals at HitechDigital started off by deriving a smarter, easier way to automate unstructured data extraction workflows.
Implementation:
Quality Check and Audit:
Dispatch:
Automated upload of comprehensive output text file after conversion, transformation, and validation