Client Profile.
The client is a healthcare firm based out of Georgia, USA, providing precision intelligence services to life science companies. With deep disease and therapy expertise, the company uses custom market research and data analysis from published journals, editorial boards or presentations by physicians at conferences to solve critical medical questions for their customers.
Business Need.
The company extracts information related to researcher’s name, location, institutes or research organization, etc. from published papers and journals to provide strategic insights to life science companies by collating it in a structured format. In order to speed up the process of information gathering and dissemination with high accuracy, the company was looking to partner with a firm which could deliver:
- Automated data collection for at least 2/3rd of webpages for specific journals on treatments related to oncology, hematology, urology, gynecology, etc.
- Auto-routing of captured data to relevant categories in database while removing repetitive entries.
Challenges.
The current processes of manual data collection from various research papers posed challenges such as:
- Dedicated 7-8 human resources round the year to extract information from websites and put it in a prescribed format.
- Delay in information gathering due to manual search for relevant data from journals each having multiple addresses, names etc. in distinct format and page layout.
- Manual data entry to client’s spreadsheet was prone to human errors such as spelling mistakes in entering physicians’ names, medicinal jargons, etc.
- Flawed insights derived from database prepared manually with unstructured datasets.
Solution.
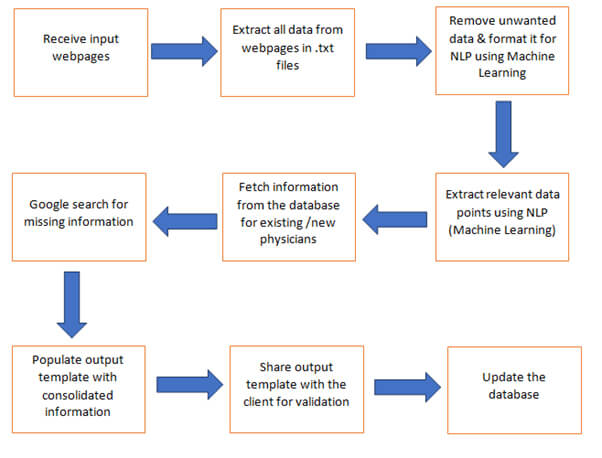
An automated workflow was designed to collect data from multiple sources and enter it into a predefined format. The process would include:
- Collection of data from webpages and medical publications specified by the client using NLP algorithm developed by HitechDigital’s automation specialist
- Deployment of RPA bots – embedded with NLP algorithm to enable formatting of data and collating it with existing database
- Removal and merger of duplicate entries and addition of entries for new physicians to help client get an exhaustive set of information
- An intuitive data summary dashboard to track performance
Approach.
- Receipt of journal and publication details such as source URLs with priority, disease area, journal name, comments and editorial board links.
- Analyze source links and extract all details and create a dataset of all diseases related research work.
- Deployment of NLP:
- The bots had to be customized to address multiple formats and varying positions of data to be extracted in the publications.
- Developing customized bots to address varying positions of data due to distinct publications formats, presentation compilation etc.
- Deployment of NLP algorithms to extract complete HTML files on web to .txt files formats.
- The algorithms would interpret certain words through the procedure of stemming and lemmatization to find specific information and populate it in Excel spreadsheets with specified formats.
- Extraction of relevant information such as physician name, degree, clinical role, country, and job position.
- Ready the database with complete information:
- Comparison of information in client’s database against the newly formed database derived from web according to physicians names by collating both the worksheets.
- Deploying RPA tools to merge duplicate entries for the same physician to find exhaustive information at once place and establish ease in decision making.
- Manual data collection to add information on physicians whose names were not enlisted in the input-forms but are found in the clients database.
- Quality checks and plugging gaps:
- Quality checks of random sampling by verification against the existing data.
- Fixing of NLP algorithms as and when errors encountered to raise quality by 8%-10%.
- Developing of separate NLP algorithms to scrape websites that are blocked, have captcha codes or are prohibited for bots for automation and uplift the quality by 5% -10%.
- Dispatch and delivery:
- Sharing of the final database with the client and creation of output database template upon approval and dumping data into their application.
- Inclusion of details such as physician name, degree, clinical role, country, and job position in database upload template.
- Generation of intuitive output report and the prescribed database template in two lists – Names of physicians existing in the database and names of new physicians collected from journals/editorial boards.
Business Impact.
Reduced human intervention
Increased data accuracy
Savings on 6-7 FTEs
Optimized process efficiency