

- Data preparation for machine learning has a direct impact on model accuracy, fairness, and business value.
- Datasets prepared well improve signal-to-noise ratios, prevent overfitting, and enhance model interpretability.
- Addressing challenges requires specialized techniques, cross-functional expertise, and systematic approaches throughout the ML pipeline.
Table of Contents
- What is data preparation for machine learning
- Importance of data preparation for machine learning
- Top data preparation challenges and solutions
- Diverse and complex data sources
- Large data volume and velocity
- Insufficient understanding through profiling
- Data inaccuracies and inconsistencies
- Feature engineering and transformation complexities
- Bias and fairness issues
- Data security in machine learning and privacy compliance risks
- Resource constraints and skills gap
- Conclusion
Data preparation for machine learning continues to be one of the most persistent challenges AI professionals face. Substandard training data is capable of derailing well-planned projects. Fragmented sources, inconsistent quality standards, and embedded bias all directly affect model accuracy, fairness outcomes, and downstream business value.
For ML engineers and data scientists working on production-grade systems today, mastering data preparation techniques is no longer optional. As organizations demand both high-performance metrics and ethical compliance from their models at scale, this article explains what is data preparation and also outlines eight core data preparation challenges along with practical strategies like hiring ai training data services address each of them within real-world workflows.
Tackling these issues early during preprocessing rather than post-training improves performance while ensuring that outputs remain reliable across diverse applications where trust matters as much as predictive power.
Understanding data preparation and why this stage matters is essential before addressing specific obstacles.
What is data preparation for machine learning
Machine learning data preparation is the task of cleaning, structuring, and preparing raw data for modeling. It encompasses a number of important steps such as dealing with missing values, deleting duplicates, error correction, and encoding categorical values. Data normalization or scaling is also done to put the features on a common scale. Feature extraction and feature selection are also done to enhance model performance.
Correct data preparation improves model performance, diminishes bias, and accelerates training. It is an essential step within the machine learning pipeline that makes sure that the algorithm is able to learn useful patterns from trustworthy, high-quality input data.
Importance of data preparation for machine learning
Effective preprocessing data for machine learning, transformation routines like normalization or binning schemes—and structured feature selection—all contribute directly to algorithmic success across classification tasks or regression problems alike. Well-prepared datasets raise signal-to-noise ratios so that models can focus on meaningful patterns instead of reacting to noise introduced by raw inputs.
Robust preprocessing also helps prevent overfitting caused by anomalies or outliers, while making models more resilient against small input variations—a critical factor when deploying AI outside controlled lab settings into dynamic environments.
Clean training sets speeds up convergence in gradient-based optimization algorithms by removing noisy datapoints that waste compute cycles without adding useful information. At the same time, improved fairness comes: thoughtful handling of imbalanced classes—for example, in healthcare datasets skewed toward majority populations—supports more equitable predictions under growing regulatory scrutiny around automated decision-making systems today.
Finally—as transformations align better with domain semantics during early-stage processing—the resulting models often become easier not just for developers but also non-specialist stakeholders to interpret clearly before deployment into high-stakes contexts such as diagnostics pipelines or financial risk scoring tools.
Top data preparation challenges and solutions
The following are the major challenges that arise during the preparation of a dataset for machine learning and the corresponding data transformation techniques and strategies that help resolve them.
1. Diverse and complex data sources
Modern machine learning projects often pull from multiple systems—each using different formats, schemas, or structures. Teams frequently face difficulties accessing enterprise datasets scattered across ERP platforms, CRMs, or legacy databases—all governed by their own access protocols.
The challenge grows when structured tables must be combined with semi-structured logs or unstructured documents—each requiring its own preprocessing strategy. Conflicts in naming conventions (e.g., “customer_id” vs. “clientID”), measurement units, or recording methods further complicate integration efforts.
Maintaining consistency becomes even harder when merging records collected under different processes, time periods, or quality standards.
To manage these integration issues effectively, teams can adopt several architectural strategies:
How to address it:
- Build connector frameworks alongside schema mapping tools
- Define acquisition strategies supported by transformation rules
- Create metadata catalogs that capture provenance details
Use Master Data Management practices to unify representations of core entities across environments. Architectures like data lakes—or lakehouses—can accommodate diverse formats while preserving both raw inputs and standardized views.
Scale image, text, and video annotation with our experts
Achieve your AI model accuracy with quality annotation
2. Large data volume and velocity
Traditional tooling struggles at the scale required for modern ML workloads — especially those involving billions of rows processed through compute-intensive transformations. Volume-related bottlenecks worsen without specialized hardware; velocity adds pressure as real-time applications require constant data flow. This puts additional strain on low-latency processing pipelines.
These constraints force trade-offs between thorough preprocessing and available capacity, storage limits, and budget ceilings.
How to address it:
Leverage distributed computing frameworks like Spark or Dask to parallelize tasks efficiently over clusters during batch stages. Apply sampling techniques early, so representative subsets guide exploration before scaling up full workflows.
For high-throughput scenarios, use stream processing engines capable of online transformation; optimize I/O performance via columnar storage formats such as Parquet; deploy elastic cloud infrastructure services that adjust dynamically based on workload intensity.
3. Insufficient understanding through profiling
Many teams underestimate how critical dataset assessment is before modeling begins — letting hidden issues like skewed distributions or latent bias surface only after major development investment has been made.
Common failure patterns include relying on small samples that miss edge cases, assuming upstream controls caught every anomaly, and writing masking logic instead of fixing root causes directly in source-level corrections.
How to address it:
Make Exploratory Data Analysis a formal project phase—not just an ad hoc task—to ensure deep familiarity before pipeline decisions are finalized. Adopt automated profiling tools such as Pandas Profiling or Great Expectations to scan datasets along key dimensions including completeness metrics, distribution shapes, outlier thresholds—and flag areas needing manual review.
Advanced visualization helps uncover multi-dimensional relationships not visible in tabular summaries alone. Define business context up front so findings align technically and strategically—and document everything thoroughly so future steps remain traceable back to evidence-based insights.
4. Data inaccuracies and inconsistencies
Inaccuracies are a recurring issue in data preparation for AI, often showing up as measurement errors, manual entry mistakes, or extreme outliers that distort model training. These problems frequently occur alongside missing values—especially when patterns of absence are complex enough to make simple imputation counterproductive.
Inconsistencies add another layer of difficulty through formatting mismatches (e.g., US vs. EU date formats), incompatible units, or standardization challenges like resolving name variations across international address schemas. Outdated records can also introduce obsolete signals into models meant to reflect current behavior.
To manage these risks effectively during preprocessing, teams can apply several targeted strategies:
How to address it:
- Apply validation rules grounded in domain knowledge early on
- Use multivariate outlier detection—not just single-variable thresholds—to flag anomalies
- Choose advanced imputation methods that account for structural relationships within the data
For inconsistency resolution: combine rule-based logic with fuzzy matching techniques to reconcile format differences without losing semantic meaning. Schedule regular freshness checks so that outdated entries don’t skew results downstream. Include expert review steps within pipelines to ensure transformations preserve business context.
5. Feature engineering and transformation complexities
Designing effective features means balancing automated tools against contextual insights from subject matter experts. Data scientists must evaluate combinations carefully — not every derived feature adds value; some may simply amplify noise if not tied back to clear hypotheses.
Transformation choices further complicate things: scaling approaches, encoding schemes, and dimensionality reduction methods must align closely with the dataset’s structure. They also need to respect modeling constraints—all while avoiding leakage between training/validation splits.
Many projects also require enrichment using external sources or proprietary knowledge bases to build datasets that truly represent real-world conditions.
How to address it:
Base feature creation on testable hypotheses linked directly to modeling goals; this keeps focus on meaningful signal rather than artifacts alone.
Use cross-validation-aware protocols when applying transformations — ensuring no contamination occurs—and validate impact through controlled experiments measuring performance and interpretability.
6. Bias and fairness issues
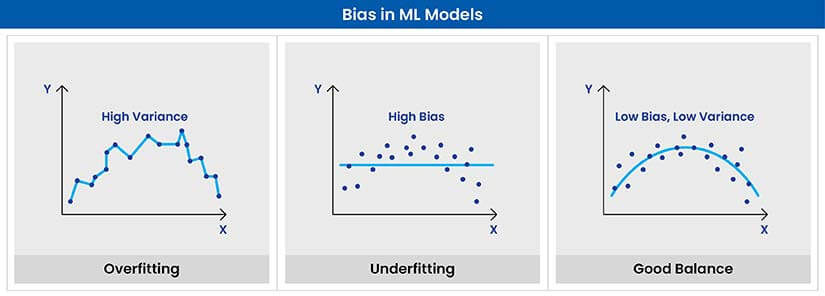
Bias enters ML workflows from multiple directions: historical bias baked into source data, sampling bias underrepresenting certain groups, label bias shaped by subjective annotations, or measurement bias introduced during attribute collection—all difficult to detect unless explicitly audited beforehand.
Naive preprocessing decisions can worsen inequities—for example, dropping rows with nulls might disproportionately remove marginalized populations’ representation entirely.
How to address it:
-
Assessment & detection
- Run structured audits during exploratory analysis phases (using tools like AIF360)
- Apply fairness metrics across protected demographic attributes
- Integrate detection modules at key pipeline checkpoints
-
Mitigation techniques
- Resample inputs where group imbalance exists
- Re-weigh observations based on population distribution
- Use equity-aware preprocessing algorithms designed specifically for fair representation
Fairness should be embedded directly into formalized preparation workflows—not treated as optional—as regulatory scrutiny continues to rise around ethical AI deployment worldwide.
Get access to reliable AI training datasets
Ensure smart model outcomes with real-world data
7. Data security in machine learning and privacy compliance risks
Organizations face a serious risk of exposing sensitive information during AI data preparation, especially when data moves across systems or becomes accessible to broader teams. These vulnerabilities span the entire life cycle—from ingestion through transformation—creating multiple exposure points that require protection.
Adding to this complexity are evolving regulations like GDPR and CCPA, which impose strict requirements on how personal data can be accessed, processed, or retained within ML workflows. Teams must balance the need for comprehensive datasets against legal obligations regarding privacy preservation.
How to address it:
- Enforce strong access controls using role-based permissions
- Integrate Privacy Enhancing Techniques such as differential privacy, k-anonymization, or synthetic data generation (e.g., simulating patient records without revealing actual identities)
- Apply secure handling protocols throughout every stage of the pipeline
- Maintain auditable logs of transformations alongside formal documentation demonstrating regulatory alignment
8. Resource constraints and skills gap
Thorough data preparation for machine learning is resource-intensive — requiring time, specialized tools, and multidisciplinary expertise spanning statistics, domain knowledge, and engineering practices rarely found in one individual.
This creates tension between ideal processes and business pressure for rapid delivery; as a result, many teams cut corners that compromise model quality over time.
How to address it:
Prioritize tasks based on downstream impact so limited resources focus where they matter most. Automate standard steps using low-code platforms, such as Trifacta or Alteryx; reserve expert input only where human judgment adds value.
Build cross-functional teams combining complementary skill sets across roles — or outsource specialized workstreams by engaging AI data training services tailored toward specific project needs.
Prepared accurate training data for food waste assessment

A Swiss food waste analytics company needed to train machine learning models to identify and categorize food waste from thousands of kitchen waste images. They struggled to label diverse, overlapping food items, including regional European dishes, to create a good training dataset.
HitechDigital’s team annotated the images with bounding boxes, segmentation masks and classification labels. By referencing a master food repository and doing quality checks, their team ensured consistent, high accuracy annotations for good model training.
The final deliverables led to:
- 100% accurate annotated datasets for machine learning
- Faster food waste analytics
- Multi-metric guided insights
Conclusion
Effective data preparation for machine learning remains foundational—not optional—for building trustworthy AI systems at scale.
By addressing machine learning challenges involving source integration, high-volume processing demands, profiling limitations, feature construction complexity, bias detection strategies, security safeguards, and organizational capability gaps—organizations gain an operational edge directly tied to model performance outcomes.
The strategies outlined here bridge theory with implementation realities applicable across industries—and position those who invest early as leaders, not just in predictive power but also in fairness, compliance, efficiency, and trustworthiness.
Get clean, verified, and consistent training data
Use our QA best practices for reliable datasets

